
Easy Macro Recorder 4.2.5 serial key or number

Easy Macro Recorder 4.2.5 serial key or number
Chapter 4: Configuring PuTTY
Previous | Contents | Index | Next
This chapter describes all the configuration options in PuTTY.
PuTTY is configured using the control panel that comes up before you start a session. Some options can also be changed in the middle of a session, by selecting ‘Change Settings’ from the window menu.
4.1 The Session panel
The Session configuration panel contains the basic options you need to specify in order to open a session at all, and also allows you to save your settings to be reloaded later.
4.1.1 The host name section
The top box on the Session panel, labelled ‘Specify your connection by host name’, contains the details that need to be filled in before PuTTY can open a session at all.
- The ‘Host Name’ box is where you type the name, or the IP address, of the server you want to connect to.
- The ‘Connection type’ radio buttons let you choose what type of connection you want to make: a raw connection, a Telnet connection, an Rlogin connection, an SSH connection, or a connection to a local serial line. (See section 1.2 for a summary of the differences between SSH, Telnet and rlogin; see section 3.6 for an explanation of ‘raw’ connections; see section 3.7 for information about using a serial line.)
- The ‘Port’ box lets you specify which port number on the server to connect to. If you select Telnet, Rlogin, or SSH, this box will be filled in automatically to the usual value, and you will only need to change it if you have an unusual server. If you select Raw mode, you will almost certainly need to fill in the ‘Port’ box yourself.
If you select ‘Serial’ from the ‘Connection type’ radio buttons, the ‘Host Name’ and ‘Port’ boxes are replaced by ‘Serial line’ and ‘Speed’; see section 4.29 for more details of these.
4.1.2 Loading and storing saved sessions
The next part of the Session configuration panel allows you to save your preferred PuTTY options so they will appear automatically the next time you start PuTTY. It also allows you to create saved sessions, which contain a full set of configuration options plus a host name and protocol. A saved session contains all the information PuTTY needs to start exactly the session you want.
- To save your default settings: first set up the settings the way you want them saved. Then come back to the Session panel. Select the ‘Default Settings’ entry in the saved sessions list, with a single click. Then press the ‘Save’ button.
If there is a specific host you want to store the details of how to connect to, you should create a saved session, which will be separate from the Default Settings.
- To save a session: first go through the rest of the configuration box setting up all the options you want. Then come back to the Session panel. Enter a name for the saved session in the ‘Saved Sessions’ input box. (The server name is often a good choice for a saved session name.) Then press the ‘Save’ button. Your saved session name should now appear in the list box.
You can also save settings in mid-session, from the ‘Change Settings’ dialog. Settings changed since the start of the session will be saved with their current values; as well as settings changed through the dialog, this includes changes in window size, window title changes sent by the server, and so on.
- To reload a saved session: single-click to select the session name in the list box, and then press the ‘Load’ button. Your saved settings should all appear in the configuration panel.
- To modify a saved session: first load it as described above. Then make the changes you want. Come back to the Session panel, and press the ‘Save’ button. The new settings will be saved over the top of the old ones.
To save the new settings under a different name, you can enter the new name in the ‘Saved Sessions’ box, or single-click to select a session name in the list box to overwrite that session. To save ‘Default Settings’, you must single-click the name before saving.
- To start a saved session immediately: double-click on the session name in the list box.
- To delete a saved session: single-click to select the session name in the list box, and then press the ‘Delete’ button.
Each saved session is independent of the Default Settings configuration. If you change your preferences and update Default Settings, you must also update every saved session separately.
Saved sessions are stored in the Registry, at the location
If you need to store them in a file, you could try the method described in section 4.30.
4.1.3 ‘Close window on exit’
Finally in the Session panel, there is an option labelled ‘Close window on exit’. This controls whether the PuTTY terminal window disappears as soon as the session inside it terminates. If you are likely to want to copy and paste text out of the session after it has terminated, or restart the session, you should arrange for this option to be off.
‘Close window on exit’ has three settings. ‘Always’ means always close the window on exit; ‘Never’ means never close on exit (always leave the window open, but inactive). The third setting, and the default one, is ‘Only on clean exit’. In this mode, a session which terminates normally will cause its window to close, but one which is aborted unexpectedly by network trouble or a confusing message from the server will leave the window up.
4.2 The Logging panel
The Logging configuration panel allows you to save log files of your PuTTY sessions, for debugging, analysis or future reference.
The main option is a radio-button set that specifies whether PuTTY will log anything at all. The options are:
- ‘None’. This is the default option; in this mode PuTTY will not create a log file at all.
- ‘Printable output’. In this mode, a log file will be created and written to, but only printable text will be saved into it. The various terminal control codes that are typically sent down an interactive session alongside the printable text will be omitted. This might be a useful mode if you want to read a log file in a text editor and hope to be able to make sense of it.
- ‘All session output’. In this mode, everything sent by the server into your terminal session is logged. If you view the log file in a text editor, therefore, you may well find it full of strange control characters. This is a particularly useful mode if you are experiencing problems with PuTTY's terminal handling: you can record everything that went to the terminal, so that someone else can replay the session later in slow motion and watch to see what went wrong.
- ‘SSH packets’. In this mode (which is only used by SSH connections), the SSH message packets sent over the encrypted connection are written to the log file (as well as Event Log entries). You might need this to debug a network-level problem, or more likely to send to the PuTTY authors as part of a bug report. BE WARNED that if you log in using a password, the password can appear in the log file; see section 4.2.5 for options that may help to remove sensitive material from the log file before you send it to anyone else.
- ‘SSH packets and raw data’. In this mode, as well as the decrypted packets (as in the previous mode), the raw (encrypted, compressed, etc) packets are also logged. This could be useful to diagnose corruption in transit. (The same caveats as the previous mode apply, of course.)
Note that the non-SSH logging options (‘Printable output’ and ‘All session output’) only work with PuTTY proper; in programs without terminal emulation (such as Plink), they will have no effect, even if enabled via saved settings.
4.2.1 ‘Log file name’
In this edit box you enter the name of the file you want to log the session to. The ‘Browse’ button will let you look around your file system to find the right place to put the file; or if you already know exactly where you want it to go, you can just type a pathname into the edit box.
There are a few special features in this box. If you use the character in the file name box, PuTTY will insert details of the current session in the name of the file it actually opens. The precise replacements it will do are:
- will be replaced by the current year, as four digits.
- will be replaced by the current month, as two digits.
- will be replaced by the current day of the month, as two digits.
- will be replaced by the current time, as six digits (HHMMSS) with no punctuation.
- will be replaced by the host name you are connecting to.
- will be replaced by the port number you are connecting to on the target host.
For example, if you enter the host name , you will end up with files looking like
4.2.2 ‘What to do if the log file already exists’
This control allows you to specify what PuTTY should do if it tries to start writing to a log file and it finds the file already exists. You might want to automatically destroy the existing log file and start a new one with the same name. Alternatively, you might want to open the existing log file and add data to the end of it. Finally (the default option), you might not want to have any automatic behaviour, but to ask the user every time the problem comes up.
4.2.3 ‘Flush log file frequently’
This option allows you to control how frequently logged data is flushed to disc. By default, PuTTY will flush data as soon as it is displayed, so that if you view the log file while a session is still open, it will be up to date; and if the client system crashes, there's a greater chance that the data will be preserved.
However, this can incur a performance penalty. If PuTTY is running slowly with logging enabled, you could try unchecking this option. Be warned that the log file may not always be up to date as a result (although it will of course be flushed when it is closed, for instance at the end of a session).
4.2.4 ‘Include header’
This option allows you to choose whether to include a header line with the date and time when the log file is opened. It may be useful to disable this if the log file is being used as realtime input to other programs that don't expect the header line.
4.2.5 Options specific to SSH packet logging
These options only apply if SSH packet data is being logged.
The following options allow particularly sensitive portions of unencrypted packets to be automatically left out of the log file. They are only intended to deter casual nosiness; an attacker could glean a lot of useful information from even these obfuscated logs (e.g., length of password).
4.2.5.1 ‘Omit known password fields’
When checked, decrypted password fields are removed from the log of transmitted packets. (This includes any user responses to challenge-response authentication methods such as ‘keyboard-interactive’.) This does not include X11 authentication data if using X11 forwarding.
Note that this will only omit data that PuTTY knows to be a password. However, if you start another login session within your PuTTY session, for instance, any password used will appear in the clear in the packet log. The next option may be of use to protect against this.
This option is enabled by default.
4.2.5.2 ‘Omit session data’
When checked, all decrypted ‘session data’ is omitted; this is defined as data in terminal sessions and in forwarded channels (TCP, X11, and authentication agent). This will usually substantially reduce the size of the resulting log file.
This option is disabled by default.
4.3 The Terminal panel
The Terminal configuration panel allows you to control the behaviour of PuTTY's terminal emulation.
4.3.1 ‘Auto wrap mode initially on’
Auto wrap mode controls what happens when text printed in a PuTTY window reaches the right-hand edge of the window.
With auto wrap mode on, if a long line of text reaches the right-hand edge, it will wrap over on to the next line so you can still see all the text. With auto wrap mode off, the cursor will stay at the right-hand edge of the screen, and all the characters in the line will be printed on top of each other.
If you are running a full-screen application and you occasionally find the screen scrolling up when it looks as if it shouldn't, you could try turning this option off.
Auto wrap mode can be turned on and off by control sequences sent by the server. This configuration option controls the default state, which will be restored when you reset the terminal (see section 3.1.3.6). However, if you modify this option in mid-session using ‘Change Settings’, it will take effect immediately.
4.3.2 ‘DEC Origin Mode initially on’
DEC Origin Mode is a minor option which controls how PuTTY interprets cursor-position control sequences sent by the server.
The server can send a control sequence that restricts the scrolling region of the display. For example, in an editor, the server might reserve a line at the top of the screen and a line at the bottom, and might send a control sequence that causes scrolling operations to affect only the remaining lines.
With DEC Origin Mode on, cursor coordinates are counted from the top of the scrolling region. With it turned off, cursor coordinates are counted from the top of the whole screen regardless of the scrolling region.
It is unlikely you would need to change this option, but if you find a full-screen application is displaying pieces of text in what looks like the wrong part of the screen, you could try turning DEC Origin Mode on to see whether that helps.
DEC Origin Mode can be turned on and off by control sequences sent by the server. This configuration option controls the default state, which will be restored when you reset the terminal (see section 3.1.3.6). However, if you modify this option in mid-session using ‘Change Settings’, it will take effect immediately.
4.3.3 ‘Implicit CR in every LF’
Most servers send two control characters, CR and LF, to start a new line of the screen. The CR character makes the cursor return to the left-hand side of the screen. The LF character makes the cursor move one line down (and might make the screen scroll).
Some servers only send LF, and expect the terminal to move the cursor over to the left automatically. If you come across a server that does this, you will see a stepped effect on the screen, like this:
If this happens to you, try enabling the ‘Implicit CR in every LF’ option, and things might go back to normal:
4.3.4 ‘Implicit LF in every CR’
Most servers send two control characters, CR and LF, to start a new line of the screen. The CR character makes the cursor return to the left-hand side of the screen. The LF character makes the cursor move one line down (and might make the screen scroll).
Some servers only send CR, and so the newly written line is overwritten by the following line. This option causes a line feed so that all lines are displayed.
4.3.5 ‘Use background colour to erase screen’
Not all terminals agree on what colour to turn the screen when the server sends a ‘clear screen’ sequence. Some terminals believe the screen should always be cleared to the default background colour. Others believe the screen should be cleared to whatever the server has selected as a background colour.
There exist applications that expect both kinds of behaviour. Therefore, PuTTY can be configured to do either.
With this option disabled, screen clearing is always done in the default background colour. With this option enabled, it is done in the current background colour.
Background-colour erase can be turned on and off by control sequences sent by the server. This configuration option controls the default state, which will be restored when you reset the terminal (see section 3.1.3.6). However, if you modify this option in mid-session using ‘Change Settings’, it will take effect immediately.
4.3.6 ‘Enable blinking text’
The server can ask PuTTY to display text that blinks on and off. This is very distracting, so PuTTY allows you to turn blinking text off completely.
When blinking text is disabled and the server attempts to make some text blink, PuTTY will instead display the text with a bolded background colour.
Blinking text can be turned on and off by control sequences sent by the server. This configuration option controls the default state, which will be restored when you reset the terminal (see section 3.1.3.6). However, if you modify this option in mid-session using ‘Change Settings’, it will take effect immediately.
4.3.7 ‘Answerback to ^E’
This option controls what PuTTY will send back to the server if the server sends it the ^E enquiry character. Normally it just sends the string ‘PuTTY’.
If you accidentally write the contents of a binary file to your terminal, you will probably find that it contains more than one ^E character, and as a result your next command line will probably read ‘PuTTYPuTTYPuTTY...’ as if you had typed the answerback string multiple times at the keyboard. If you set the answerback string to be empty, this problem should go away, but doing so might cause other problems.
Note that this is not the feature of PuTTY which the server will typically use to determine your terminal type. That feature is the ‘Terminal-type string’ in the Connection panel; see section 4.15.3 for details.
You can include control characters in the answerback string using notation. (Use to get a literal .)
4.3.8 ‘Local echo’
With local echo disabled, characters you type into the PuTTY window are not echoed in the window by PuTTY. They are simply sent to the server. (The server might choose to echo them back to you; this can't be controlled from the PuTTY control panel.)
Some types of session need local echo, and many do not. In its default mode, PuTTY will automatically attempt to deduce whether or not local echo is appropriate for the session you are working in. If you find it has made the wrong decision, you can use this configuration option to override its choice: you can force local echo to be turned on, or force it to be turned off, instead of relying on the automatic detection.
4.3.9 ‘Local line editing’
Normally, every character you type into the PuTTY window is sent immediately to the server the moment you type it.
If you enable local line editing, this changes. PuTTY will let you edit a whole line at a time locally, and the line will only be sent to the server when you press Return. If you make a mistake, you can use the Backspace key to correct it before you press Return, and the server will never see the mistake.
Since it is hard to edit a line locally without being able to see it, local line editing is mostly used in conjunction with local echo (section 4.3.8). This makes it ideal for use in raw mode or when connecting to MUDs or talkers. (Although some more advanced MUDs do occasionally turn local line editing on and turn local echo off, in order to accept a password from the user.)
Some types of session need local line editing, and many do not. In its default mode, PuTTY will automatically attempt to deduce whether or not local line editing is appropriate for the session you are working in. If you find it has made the wrong decision, you can use this configuration option to override its choice: you can force local line editing to be turned on, or force it to be turned off, instead of relying on the automatic detection.
4.3.10 Remote-controlled printing
A lot of VT100-compatible terminals support printing under control of the remote server (sometimes called ‘passthrough printing’). PuTTY supports this feature as well, but it is turned off by default.
To enable remote-controlled printing, choose a printer from the ‘Printer to send ANSI printer output to’ drop-down list box. This should allow you to select from all the printers you have installed drivers for on your computer. Alternatively, you can type the network name of a networked printer (for example, ) even if you haven't already installed a driver for it on your own machine.
When the remote server attempts to print some data, PuTTY will send that data to the printer raw - without translating it, attempting to format it, or doing anything else to it. It is up to you to ensure your remote server knows what type of printer it is talking to.
Since PuTTY sends data to the printer raw, it cannot offer options such as portrait versus landscape, print quality, or paper tray selection. All these things would be done by your PC printer driver (which PuTTY bypasses); if you need them done, you will have to find a way to configure your remote server to do them.
To disable remote printing again, choose ‘None (printing disabled)’ from the printer selection list. This is the default state.
4.4 The Keyboard panel
The Keyboard configuration panel allows you to control the behaviour of the keyboard in PuTTY. The correct state for many of these settings depends on what the server to which PuTTY is connecting expects. With a Unix server, this is likely to depend on the or entry it uses, which in turn is likely to be controlled by the ‘Terminal-type string’ setting in the Connection panel; see section 4.15.3 for details. If none of the settings here seems to help, you may find question A.7.13 to be useful.
4.4.1 Changing the action of the Backspace key
Some terminals believe that the Backspace key should send the same thing to the server as Control-H (ASCII code 8). Other terminals believe that the Backspace key should send ASCII code 127 (usually known as Control-?) so that it can be distinguished from Control-H. This option allows you to choose which code PuTTY generates when you press Backspace.
If you are connecting over SSH, PuTTY by default tells the server the value of this option (see section 4.25.2), so you may find that the Backspace key does the right thing either way. Similarly, if you are connecting to a Unix system, you will probably find that the Unix command lets you configure which the server expects to see, so again you might not need to change which one PuTTY generates. On other systems, the server's expectation might be fixed and you might have no choice but to configure PuTTY.
If you do have the choice, we recommend configuring PuTTY to generate Control-? and configuring the server to expect it, because that allows applications such as to use Control-H for help.
(Typing Shift-Backspace will cause PuTTY to send whichever code isn't configured here as the default.)
4.4.2 Changing the action of the Home and End keys
The Unix terminal emulator disagrees with the rest of the world about what character sequences should be sent to the server by the Home and End keys.
, and other terminals, send for the Home key, and for the End key. sends for the Home key and for the End key.
If you find an application on which the Home and End keys aren't working, you could try switching this option to see if it helps.
4.4.3 Changing the action of the function keys and keypad
This option affects the function keys (F1 to F12) and the top row of the numeric keypad.
- In the default mode, labelled , the function keys generate sequences like , and so on. This matches the general behaviour of Digital's terminals.
- In Linux mode, F6 to F12 behave just like the default mode, but F1 to F5 generate through to . This mimics the Linux virtual console.
- In Xterm R6 mode, F5 to F12 behave like the default mode, but F1 to F4 generate through to , which are the sequences produced by the top row of the keypad on Digital's terminals.
- In VT400 mode, all the function keys behave like the default mode, but the actual top row of the numeric keypad generates through to .
- In VT100+ mode, the function keys generate through to
- In SCO mode, the function keys F1 to F12 generate through to . Together with shift, they generate through to . With control they generate through to , and with shift and control together they generate through to .
If you don't know what any of this means, you probably don't need to fiddle with it.
4.4.4 Controlling Application Cursor Keys mode
Application Cursor Keys mode is a way for the server to change the control sequences sent by the arrow keys. In normal mode, the arrow keys send through to . In application mode, they send through to .
Application Cursor Keys mode can be turned on and off by the server, depending on the application. PuTTY allows you to configure the initial state.
You can also disable application cursor keys mode completely, using the ‘Features’ configuration panel; see section 4.6.1.
4.4.5 Controlling Application Keypad mode
Application Keypad mode is a way for the server to change the behaviour of the numeric keypad.
In normal mode, the keypad behaves like a normal Windows keypad: with NumLock on, the number keys generate numbers, and with NumLock off they act like the arrow keys and Home, End etc.
In application mode, all the keypad keys send special control sequences, including Num Lock. Num Lock stops behaving like Num Lock and becomes another function key.
Depending on which version of Windows you run, you may find the Num Lock light still flashes on and off every time you press Num Lock, even when application mode is active and Num Lock is acting like a function key. This is unavoidable.
Application keypad mode can be turned on and off by the server, depending on the application. PuTTY allows you to configure the initial state.
You can also disable application keypad mode completely, using the ‘Features’ configuration panel; see section 4.6.1.
4.4.6 Using NetHack keypad mode
PuTTY has a special mode for playing NetHack. You can enable it by selecting ‘NetHack’ in the ‘Initial state of numeric keypad’ control.
In this mode, the numeric keypad keys 1-9 generate the NetHack movement commands (). The 5 key generates the command (do nothing).
In addition, pressing Shift or Ctrl with the keypad keys generate the Shift- or Ctrl-keys you would expect (e.g. keypad-7 generates ‘’, so Shift-keypad-7 generates ‘’ and Ctrl-keypad-7 generates Ctrl-Y); these commands tell NetHack to keep moving you in the same direction until you encounter something interesting.
For some reason, this feature only works properly when Num Lock is on. We don't know why.
4.4.7 Enabling a DEC-like Compose key
DEC terminals have a Compose key, which provides an easy-to-remember way of typing accented characters. You press Compose and then type two more characters. The two characters are ‘combined’ to produce an accented character. The choices of character are designed to be easy to remember; for example, composing ‘e’ and ‘`’ produces the ‘è’ character.
If your keyboard has a Windows Application key, it acts as a Compose key in PuTTY. Alternatively, if you enable the ‘AltGr acts as Compose key’ option, the AltGr key will become a Compose key.
4.4.8 ‘Control-Alt is different from AltGr’
Some old keyboards do not have an AltGr key, which can make it difficult to type some characters. PuTTY can be configured to treat the key combination Ctrl + Left Alt the same way as the AltGr key.
By default, this checkbox is checked, and the key combination Ctrl + Left Alt does something completely different. PuTTY's usual handling of the left Alt key is to prefix the Escape (Control-) character to whatever character sequence the rest of the keypress would generate. For example, Alt-A generates Escape followed by . So Alt-Ctrl-A would generate Escape, followed by Control-A.
If you uncheck this box, Ctrl-Alt will become a synonym for AltGr, so you can use it to type extra graphic characters if your keyboard has any.
(However, Ctrl-Alt will never act as a Compose key, regardless of the setting of ‘AltGr acts as Compose key’ described in section 4.4.7.)
4.5 The Bell panel
The Bell panel controls the terminal bell feature: the server's ability to cause PuTTY to beep at you.
In the default configuration, when the server sends the character with ASCII code 7 (Control-G), PuTTY will play the Windows Default Beep sound. This is not always what you want the terminal bell feature to do; the Bell panel allows you to configure alternative actions.
4.5.1 ‘Set the style of bell’
This control allows you to select various different actions to occur on a terminal bell:
- Selecting ‘None’ disables the bell completely. In this mode, the server can send as many Control-G characters as it likes and nothing at all will happen.
- ‘Make default system alert sound’ is the default setting. It causes the Windows ‘Default Beep’ sound to be played. To change what this sound is, or to test it if nothing seems to be happening, use the Sound configurer in the Windows Control Panel.
- ‘Visual bell’ is a silent alternative to a beeping computer. In this mode, when the server sends a Control-G, the whole PuTTY window will flash white for a fraction of a second.
- ‘Beep using the PC speaker’ is self-explanatory.
- ‘Play a custom sound file’ allows you to specify a particular sound file to be used by PuTTY alone, or even by a particular individual PuTTY session. This allows you to distinguish your PuTTY beeps from any other beeps on the system. If you select this option, you will also need to enter the name of your sound file in the edit control ‘Custom sound file to play as a bell’.
4.5.2 ‘Taskbar/caption indication on bell’
This feature controls what happens to the PuTTY window's entry in the Windows Taskbar if a bell occurs while the window does not have the input focus.
In the default state (‘Disabled’) nothing unusual happens.
If you select ‘Steady’, then when a bell occurs and the window is not in focus, the window's Taskbar entry and its title bar will change colour to let you know that PuTTY session is asking for your attention. The change of colour will persist until you select the window, so you can leave several PuTTY windows minimised in your terminal, go away from your keyboard, and be sure not to have missed any important beeps when you get back.
‘Flashing’ is even more eye-catching: the Taskbar entry will continuously flash on and off until you select the window.
4.5.3 ‘Control the bell overload behaviour’
A common user error in a terminal session is to accidentally run the Unix command (or equivalent) on an inappropriate file type, such as an executable, image file, or ZIP file. This produces a huge stream of non-text characters sent to the terminal, which typically includes a lot of bell characters. As a result of this the terminal often doesn't stop beeping for ten minutes, and everybody else in the office gets annoyed.
To try to avoid this behaviour, or any other cause of excessive beeping, PuTTY includes a bell overload management feature. In the default configuration, receiving more than five bell characters in a two-second period will cause the overload feature to activate. Once the overload feature is active, further bells will have no effect at all, so the rest of your binary file will be sent to the screen in silence. After a period of five seconds during which no further bells are received, the overload feature will turn itself off again and bells will be re-enabled.
If you want this feature completely disabled, you can turn it off using the checkbox ‘Bell is temporarily disabled when over-used’.
Alternatively, if you like the bell overload feature but don't agree with the settings, you can configure the details: how many bells constitute an overload, how short a time period they have to arrive in to do so, and how much silent time is required before the overload feature will deactivate itself.
Bell overload mode is always deactivated by any keypress in the terminal. This means it can respond to large unexpected streams of data, but does not interfere with ordinary command-line activities that generate beeps (such as filename completion).
4.6 The Features panel
PuTTY's terminal emulation is very highly featured, and can do a lot of things under remote server control. Some of these features can cause problems due to buggy or strangely configured server applications.
The Features configuration panel allows you to disable some of PuTTY's more advanced terminal features, in case they cause trouble.
4.6.1 Disabling application keypad and cursor keys
Application keypad mode (see section 4.4.5) and application cursor keys mode (see section 4.4.4) alter the behaviour of the keypad and cursor keys. Some applications enable these modes but then do not deal correctly with the modified keys. You can force these modes to be permanently disabled no matter what the server tries to do.
4.6.2 Disabling -style mouse reporting
PuTTY allows the server to send control codes that let it take over the mouse and use it for purposes other than copy and paste. Applications which use this feature include the text-mode web browser , the Usenet newsreader version 4, and the file manager (Midnight Commander).
If you find this feature inconvenient, you can disable it using the ‘Disable xterm-style mouse reporting’ control. With this box ticked, the mouse will always do copy and paste in the normal way.
Note that even if the application takes over the mouse, you can still manage PuTTY's copy and paste by holding down the Shift key while you select and paste, unless you have deliberately turned this feature off (see section 4.11.2).
4.6.3 Disabling remote terminal resizing
PuTTY has the ability to change the terminal's size and position in response to commands from the server. If you find PuTTY is doing this unexpectedly or inconveniently, you can tell PuTTY not to respond to those server commands.
4.6.4 Disabling switching to the alternate screen
Many terminals, including PuTTY, support an ‘alternate screen’. This is the same size as the ordinary terminal screen, but separate. Typically a screen-based program such as a text editor might switch the terminal to the alternate screen before starting up. Then at the end of the run, it switches back to the primary screen, and you see the screen contents just as they were before starting the editor.
Some people prefer this not to happen. If you want your editor to run in the same screen as the rest of your terminal activity, you can disable the alternate screen feature completely.
4.6.5 Disabling remote window title changing
PuTTY has the ability to change the window title in response to commands from the server. If you find PuTTY is doing this unexpectedly or inconveniently, you can tell PuTTY not to respond to those server commands.
4.6.6 Response to remote window title querying
PuTTY can optionally provide the xterm service of allowing server applications to find out the local window title. This feature is disabled by default, but you can turn it on if you really want it.
NOTE that this feature is a potential security hazard. If a malicious application can write data to your terminal (for example, if you merely a file owned by someone else on the server machine), it can change your window title (unless you have disabled this as mentioned in section 4.6.5) and then use this service to have the new window title sent back to the server as if typed at the keyboard. This allows an attacker to fake keypresses and potentially cause your server-side applications to do things you didn't want. Therefore this feature is disabled by default, and we recommend you do not set it to ‘Window title’ unless you really know what you are doing.
There are three settings for this option:
- ‘None’
- PuTTY makes no response whatsoever to the relevant escape sequence. This may upset server-side software that is expecting some sort of response.
- ‘Empty string’
- PuTTY makes a well-formed response, but leaves it blank. Thus, server-side software that expects a response is kept happy, but an attacker cannot influence the response string. This is probably the setting you want if you have no better ideas.
- ‘Window title’
- PuTTY responds with the actual window title. This is dangerous for the reasons described above.
4.6.7 Disabling remote scrollback clearing
PuTTY has the ability to clear the terminal's scrollback buffer in response to a command from the server. If you find PuTTY is doing this unexpectedly or inconveniently, you can tell PuTTY not to respond to that server command.
4.6.8 Disabling destructive backspace
Normally, when PuTTY receives character 127 (^?) from the server, it will perform a ‘destructive backspace’: move the cursor one space left and delete the character under it. This can apparently cause problems in some applications, so PuTTY provides the ability to configure character 127 to perform a normal backspace (without deleting a character) instead.
4.6.9 Disabling remote character set configuration
PuTTY has the ability to change its character set configuration in response to commands from the server. Some programs send these commands unexpectedly or inconveniently. In particular, BitchX (an IRC client) seems to have a habit of reconfiguring the character set to something other than the user intended.
If you find that accented characters are not showing up the way you expect them to, particularly if you're running BitchX, you could try disabling the remote character set configuration commands.
4.6.10 Disabling Arabic text shaping
PuTTY supports shaping of Arabic text, which means that if your server sends text written in the basic Unicode Arabic alphabet then it will convert it to the correct display forms before printing it on the screen.
If you are using full-screen software which was not expecting this to happen (especially if you are not an Arabic speaker and you unexpectedly find yourself dealing with Arabic text files in applications which are not Arabic-aware), you might find that the display becomes corrupted. By ticking this box, you can disable Arabic text shaping so that PuTTY displays precisely the characters it is told to display.
You may also find you need to disable bidirectional text display; see section 4.6.11.
4.6.11 Disabling bidirectional text display
PuTTY supports bidirectional text display, which means that if your server sends text written in a language which is usually displayed from right to left (such as Arabic or Hebrew) then PuTTY will automatically flip it round so that it is displayed in the right direction on the screen.
If you are using full-screen software which was not expecting this to happen (especially if you are not an Arabic speaker and you unexpectedly find yourself dealing with Arabic text files in applications which are not Arabic-aware), you might find that the display becomes corrupted. By ticking this box, you can disable bidirectional text display, so that PuTTY displays text from left to right in all situations.
You may also find you need to disable Arabic text shaping; see section 4.6.10.
4.7 The Window panel
The Window configuration panel allows you to control aspects of the PuTTY window.
4.7.1 Setting the size of the PuTTY window
The ‘Columns’ and ‘Rows’ boxes let you set the PuTTY window to a precise size. Of course you can also drag the window to a new size while a session is running.
4.7.2 What to do when the window is resized
These options allow you to control what happens when the user tries to resize the PuTTY window using its window furniture.
There are four options here:
- ‘Change the number of rows and columns’: the font size will not change. (This is the default.)
- ‘Change the size of the font’: the number of rows and columns in the terminal will stay the same, and the font size will change.
- ‘Change font size when maximised’: when the window is resized, the number of rows and columns will change, except when the window is maximised (or restored), when the font size will change. (In this mode, holding down the Alt key while resizing will also cause the font size to change.)
- ‘Forbid resizing completely’: the terminal will refuse to be resized at all.
4.7.3 Controlling scrollback
These options let you configure the way PuTTY keeps text after it scrolls off the top of the screen (see section 3.1.2).
The ‘Lines of scrollback’ box lets you configure how many lines of text PuTTY keeps. The ‘Display scrollbar’ options allow you to hide the scrollbar (although you can still view the scrollback using the keyboard as described in section 3.1.2). You can separately configure whether the scrollbar is shown in full-screen mode and in normal modes.
If you are viewing part of the scrollback when the server sends more text to PuTTY, the screen will revert to showing the current terminal contents. You can disable this behaviour by turning off ‘Reset scrollback on display activity’. You can also make the screen revert when you press a key, by turning on ‘Reset scrollback on keypress’.
4.7.4 ‘Push erased text into scrollback’
When this option is enabled, the contents of the terminal screen will be pushed into the scrollback when a server-side application clears the screen, so that your scrollback will contain a better record of what was on your screen in the past.
If the application switches to the alternate screen (see section 4.6.4 for more about this), then the contents of the primary screen will be visible in the scrollback until the application switches back again.
This option is enabled by default.
4.8 The Appearance panel
The Appearance configuration panel allows you to control aspects of the appearance of PuTTY's window.
4.8.1 Controlling the appearance of the cursor
The ‘Cursor appearance’ option lets you configure the cursor to be a block, an underline, or a vertical line. A block cursor becomes an empty box when the window loses focus; an underline or a vertical line becomes dotted.
The ‘Cursor blinks’ option makes the cursor blink on and off. This works in any of the cursor modes.
4.8.2 Controlling the font used in the terminal window
This option allows you to choose what font, in what size, the PuTTY terminal window uses to display the text in the session.
By default, you will be offered a choice from all the fixed-width fonts installed on the system, since VT100-style terminal handling expects a fixed-width font. If you tick the box marked ‘Allow selection of variable-pitch fonts’, however, PuTTY will offer variable-width fonts as well: if you select one of these, the font will be coerced into fixed-size character cells, which will probably not look very good (but can work OK with some fonts).
4.8.3 ‘Hide mouse pointer when typing in window’
If you enable this option, the mouse pointer will disappear if the PuTTY window is selected and you press a key. This way, it will not obscure any of the text in the window while you work in your session. As soon as you move the mouse, the pointer will reappear.
This option is disabled by default, so the mouse pointer remains visible at all times.
4.8.4 Controlling the window border
PuTTY allows you to configure the appearance of the window border to some extent.
The checkbox marked ‘Sunken-edge border’ changes the appearance of the window border to something more like a DOS box: the inside edge of the border is highlighted as if it sank down to meet the surface inside the window. This makes the border a little bit thicker as well. It's hard to describe well. Try it and see if you like it.
You can also configure a completely blank gap between the text in the window and the border, using the ‘Gap between text and window edge’ control. By default this is set at one pixel. You can reduce it to zero, or increase it further.
4.9 The Behaviour panel
The Behaviour configuration panel allows you to control aspects of the behaviour of PuTTY's window.
4.9.1 Controlling the window title
The ‘Window title’ edit box allows you to set the title of the PuTTY window. By default the window title will contain the host name followed by ‘PuTTY’, for example . If you want a different window title, this is where to set it.
PuTTY allows the server to send control sequences which modify the title of the window in mid-session (unless this is disabled - see section 4.6.5); the title string set here is therefore only the initial window title.
As well as the window title, there is also an sequence to modify the title of the window's icon. This makes sense in a windowing system where the window becomes an icon when minimised, such as Windows 3.1 or most X Window System setups; but in the Windows 95-like user interface it isn't as applicable.
By default, PuTTY only uses the server-supplied window title, and ignores the icon title entirely. If for some reason you want to see both titles, check the box marked ‘Separate window and icon titles’. If you do this, PuTTY's window title and Taskbar caption will change into the server-supplied icon title if you minimise the PuTTY window, and change back to the server-supplied window title if you restore it. (If the server has not bothered to supply a window or icon title, none of this will happen.)
4.9.2 ‘Warn before closing window’
If you press the Close button in a PuTTY window that contains a running session, PuTTY will put up a warning window asking if you really meant to close the window. A window whose session has already terminated can always be closed without a warning.
If you want to be able to close a window quickly, you can disable the ‘Warn before closing window’ option.
4.9.3 ‘Window closes on ALT-F4’
By default, pressing ALT-F4 causes the window to close (or a warning box to appear; see section 4.9.2). If you disable the ‘Window closes on ALT-F4’ option, then pressing ALT-F4 will simply send a key sequence to the server.
4.9.4 ‘System menu appears on ALT-Space’
If this option is enabled, then pressing ALT-Space will bring up the PuTTY window's menu, like clicking on the top left corner. If it is disabled, then pressing ALT-Space will just send to the server.
Some accessibility programs for Windows may need this option enabling to be able to control PuTTY's window successfully. For instance, Dragon NaturallySpeaking requires it both to open the system menu via voice, and to close, minimise, maximise and restore the window.
4.9.5 ‘System menu appears on Alt alone’
If this option is enabled, then pressing and releasing ALT will bring up the PuTTY window's menu, like clicking on the top left corner. If it is disabled, then pressing and releasing ALT will have no effect.
4.9.6 ‘Ensure window is always on top’
If this option is enabled, the PuTTY window will stay on top of all other windows.
4.9.7 ‘Full screen on Alt-Enter’
If this option is enabled, then pressing Alt-Enter will cause the PuTTY window to become full-screen. Pressing Alt-Enter again will restore the previous window size.
The full-screen feature is also available from the System menu, even when it is configured not to be available on the Alt-Enter key. See section 3.1.3.7.
4.10 The Translation panel
The Translation configuration panel allows you to control the translation between the character set understood by the server and the character set understood by PuTTY.
4.10.1 Controlling character set translation
During an interactive session, PuTTY receives a stream of 8-bit bytes from the server, and in order to display them on the screen it needs to know what character set to interpret them in. Similarly, PuTTY needs to know how to translate your keystrokes into the encoding the server expects. Unfortunately, there is no satisfactory mechanism for PuTTY and the server to communicate this information, so it must usually be manually configured.
There are a lot of character sets to choose from. The ‘Remote character set’ option lets you select one.
By default PuTTY will use the UTF-8 encoding of Unicode, which can represent pretty much any character; data coming from the server is interpreted as UTF-8, and keystrokes are sent UTF-8 encoded. This is what most modern distributions of Linux will expect by default. However, if this is wrong for your server, you can select a different character set using this control.
A few other notable character sets are:
- The ISO-8859 series are all standard character sets that include various accented characters appropriate for different sets of languages.
- The Win125x series are defined by Microsoft, for similar purposes. In particular Win1252 is almost equivalent to ISO-8859-1, but contains a few extra characters such as matched quotes and the Euro symbol.
- If you want the old IBM PC character set with block graphics and line-drawing characters, you can select ‘CP437’.
If you need support for a numeric code page which is not listed in the drop-down list, such as code page 866, then you can try entering its name manually ( for example) in the list box. If the underlying version of Windows has the appropriate translation table installed, PuTTY will use it.
4.10.2 ‘Treat CJK ambiguous characters as wide’
There are some Unicode characters whose width is not well-defined. In most contexts, such characters should be treated as single-width for the purposes of wrapping and so on; however, in some CJK contexts, they are better treated as double-width for historical reasons, and some server-side applications may expect them to be displayed as such. Setting this option will cause PuTTY to take the double-width interpretation.
If you use legacy CJK applications, and you find your lines are wrapping in the wrong places, or you are having other display problems, you might want to play with this setting.
This option only has any effect in UTF-8 mode (see section 4.10.1).
4.10.3 ‘Caps Lock acts as Cyrillic switch’
This feature allows you to switch between a US/UK keyboard layout and a Cyrillic keyboard layout by using the Caps Lock key, if you need to type (for example) Russian and English side by side in the same document.
Currently this feature is not expected to work properly if your native keyboard layout is not US or UK.
4.10.4 Controlling display of line-drawing characters
VT100-series terminals allow the server to send control sequences that shift temporarily into a separate character set for drawing simple lines and boxes. However, there are a variety of ways in which PuTTY can attempt to find appropriate characters, and the right one to use depends on the locally configured font. In general you should probably try lots of options until you find one that your particular font supports.
- ‘Use Unicode line drawing code points’ tries to use the box characters that are present in Unicode. For good Unicode-supporting fonts this is probably the most reliable and functional option.
- ‘Poor man's line drawing’ assumes that the font cannot generate the line and box characters at all, so it will use the , and characters to draw approximations to boxes. You should use this option if none of the other options works.
- ‘Font has XWindows encoding’ is for use with fonts that have a special encoding, where the lowest 32 character positions (below the ASCII printable range) contain the line-drawing characters. This is unlikely to be the case with any standard Windows font; it will probably only apply to custom-built fonts or fonts that have been automatically converted from the X Window System.
- ‘Use font in both ANSI and OEM modes’ tries to use the same font in two different character sets, to obtain a wider range of characters. This doesn't always work; some fonts claim to be a different size depending on which character set you try to use.
- ‘Use font in OEM mode only’ is more reliable than that, but can miss out other characters from the main character set.
4.10.5 Controlling copy and paste of line drawing characters
By default, when you copy and paste a piece of the PuTTY screen that contains VT100 line and box drawing characters, PuTTY will paste them in the form they appear on the screen: either Unicode line drawing code points, or the ‘poor man's’ line-drawing characters , and . The checkbox ‘Copy and paste VT100 line drawing chars as lqqqk’ disables this feature, so line-drawing characters will be pasted as the ASCII characters that were printed to produce them. This will typically mean they come out mostly as and , with a scattering of at the corners. This might be useful if you were trying to recreate the same box layout in another program, for example.
Note that this option only applies to line-drawing characters which were printed by using the VT100 mechanism. Line-drawing characters that were received as Unicode code points will paste as Unicode always.
4.10.6 Combining VT100 line-drawing with UTF-8
If PuTTY is configured to treat data from the server as encoded in UTF-8, then by default it disables the older VT100-style system of control sequences that cause the lower-case letters to be temporarily replaced by line drawing characters.
The rationale is that in UTF-8 mode you don't need those control sequences anyway, because all the line-drawing characters they access are available as Unicode characters already, so there's no need for applications to put the terminal into a special state to get at them.
Also, it removes a risk of the terminal accidentally getting into that state: if you accidentally write uncontrolled binary data to a non-UTF-8 terminal, it can be surprisingly common to find that your next shell prompt appears as a sequence of line-drawing characters and then you have to remember or look up how to get out of that mode. So by default, UTF-8 mode simply doesn't have a confusing mode like that to get into, accidentally or on purpose.
However, not all applications will see it that way. Even UTF-8 terminal users will still sometimes have to run software that tries to print line-drawing characters in the old-fashioned way. So the configuration option ‘Enable VT100 line drawing even in UTF-8 mode’ puts PuTTY into a hybrid mode in which it understands the VT100-style control sequences that change the meaning of the ASCII lower case letters, and understands UTF-8.
4.11 The Selection panel
The Selection panel allows you to control the way copy and paste work in the PuTTY window.
4.11.1 Changing the actions of the mouse buttons
PuTTY's copy and paste mechanism is by default modelled on the Unix application. The X Window System uses a three-button mouse, and the convention in that system is that the left button selects, the right button extends an existing selection, and the middle button pastes.
Windows often only has two mouse buttons, so when run on Windows, PuTTY is configurable. In PuTTY's default configuration (‘Compromise’), the right button pastes, and the middle button (if you have one) extends a selection.
If you have a three-button mouse and you are already used to the arrangement, you can select it using the ‘Action of mouse buttons’ control.
Alternatively, with the ‘Windows’ option selected, the middle button extends, and the right button brings up a context menu (on which one of the options is ‘Paste’). (This context menu is always available by holding down Ctrl and right-clicking, regardless of the setting of this option.)
(When PuTTY iself is running on Unix, it follows the X Window System convention.)
4.11.2 ‘Shift overrides application's use of mouse’
PuTTY allows the server to send control codes that let it take over the mouse and use it for purposes other than copy and paste. Applications which use this feature include the text-mode web browser , the Usenet newsreader version 4, and the file manager (Midnight Commander).
When running one of these applications, pressing the mouse buttons no longer performs copy and paste. If you do need to copy and paste, you can still do so if you hold down Shift while you do your mouse clicks.
However, it is possible in theory for applications to even detect and make use of Shift + mouse clicks. We don't know of any applications that do this, but in case someone ever writes one, unchecking the ‘Shift overrides application's use of mouse’ checkbox will cause Shift + mouse clicks to go to the server as well (so that mouse-driven copy and paste will be completely disabled).
If you want to prevent the application from taking over the mouse at all, you can do this using the Features control panel; see section 4.6.2.
4.11.3 Default selection mode
As described in section 3.1.1, PuTTY has two modes of selecting text to be copied to the clipboard. In the default mode (‘Normal’), dragging the mouse from point A to point B selects to the end of the line containing A, all the lines in between, and from the very beginning of the line containing B. In the other mode (‘Rectangular block’), dragging the mouse between two points defines a rectangle, and everything within that rectangle is copied.
Normally, you have to hold down Alt while dragging the mouse to select a rectangular block. Using the ‘Default selection mode’ control, you can set rectangular selection as the default, and then you have to hold down Alt to get the normal behaviour.
4.11.4 Assigning copy and paste actions to clipboards
Here you can configure which clipboard(s) are written or read by PuTTY's various copy and paste actions.
Most platforms, including Windows, have a single system clipboard. On these platforms, PuTTY provides a second clipboard-like facility by permitting you to paste the text you last selected in this window, whether or not it is currently also in the system clipboard. This is not enabled by default.
The X Window System (which underlies most Unix graphical interfaces) provides multiple clipboards (or ‘selections’), and many applications support more than one of them by a different user interface mechanism. When PuTTY itself is running on Unix, it has more configurability relating to these selections.
The two most commonly used selections are called ‘’ and ‘’; in applications supporting both, the usual behaviour is that is used by mouse-only actions (selecting text automatically copies it to , and middle-clicking pastes from ), whereas is used by explicit Copy and Paste menu items or keypresses such as Ctrl-C and Ctrl-V.
4.11.4.1 ‘Auto-copy selected text’
The checkbox ‘Auto-copy selected text to system clipboard’ controls whether or not selecting text in the PuTTY terminal window automatically has the side effect of copying it to the system clipboard, without requiring a separate user interface action.
On X, the wording of this option is changed slightly so that ‘’ is mentioned in place of the ‘system clipboard’. Text selected in the terminal window will always be automatically placed in the selection, as is conventional, but if you tick this box, it will also be placed in ‘’ at the same time.
4.11.4.2 Choosing a clipboard for UI actions
PuTTY has three user-interface actions which can be configured to paste into the terminal (not counting menu items). You can click whichever mouse button (if any) is configured to paste (see section 4.11.1); you can press Shift-Ins; or you can press Ctrl-Shift-V, although that action is not enabled by default.
You can configure which of the available clipboards each of these actions pastes from (including turning the paste action off completely). On platforms with a single system clipboard (such as Windows), the available options are to paste from that clipboard or to paste from PuTTY's internal memory of the last selected text within that window. On X, the standard options are or .
( is conceptually similar in that it also refers to the last selected text – just across all applications instead of just this window.)
The two keyboard options each come with a corresponding key to copy to the same clipboard. Whatever you configure Shift-Ins to paste from, Ctrl-Ins will copy to the same location; similarly, Ctrl-Shift-C will copy to whatever Ctrl-Shift-V pastes from.
On X, you can also enter a selection name of your choice. For example, there is a rarely-used standard selection called ‘’, which Emacs (for example) can work with if you hold down the Meta key while dragging to select or clicking to paste; if you configure a PuTTY keyboard action to access this clipboard, then you can interoperate with other applications' use of it. Another thing you could do would be to invent a clipboard name yourself, to create a special clipboard shared only between instances of PuTTY, or between just instances configured in that particular way.
4.11.5 ‘Permit control characters in pasted text’
It is possible for the clipboard to contain not just text (with newlines and tabs) but also control characters such as ESC which could have surprising effects if pasted into a terminal session, depending on what program is running on the server side. Copying text from a mischievous web page could put such characters onto the clipboard.
By default, PuTTY filters out the more unusual control characters, only letting through the more obvious text-formatting characters (newlines, tab, backspace, and DEL).
Setting this option stops this filtering; on paste, any character on the clipboard is sent to the session uncensored. This might be useful if you are deliberately using control character pasting as a simple form of scripting, for instance.
4.12 The Copy panel
The Copy configuration panel controls behaviour specifically related to copying from the terminal window to the clipboard.
4.12.1 Character classes
PuTTY will select a word at a time in the terminal window if you double-click to begin the drag. This section allows you to control precisely what is considered to be a word.
Each character is given a class, which is a small number (typically 0, 1 or 2). PuTTY considers a single word to be any number of adjacent characters in the same class. So by modifying the assignment of characters to classes, you can modify the word-by-word selection behaviour.
In the default configuration, the character classes are:
- Class 0 contains white space and control characters.
- Class 1 contains most punctuation.
- Class 2 contains letters, numbers and a few pieces of punctuation (the double quote, minus sign, period, forward slash and underscore).
So, for example, if you assign the symbol into character class 2, you will be able to select an e-mail address with just a double click.
In order to adjust these assignments, you start by selecting a group of characters in the list box. Then enter a class number in the edit box below, and press the ‘Set’ button.
This mechanism currently only covers ASCII characters, because it isn't feasible to expand the list to cover the whole of Unicode.
Character class definitions can be modified by control sequences sent by the server. This configuration option controls the default state, which will be restored when you reset the terminal (see section 3.1.3.6). However, if you modify this option in mid-session using ‘Change Settings’, it will take effect immediately.
4.12.2 Copying in Rich Text Format
If you enable ‘Copy to clipboard in RTF as well as plain text’, PuTTY will write formatting information to the clipboard as well as the actual text you copy. The effect of this is that if you paste into (say) a word processor, the text will appear in the word processor in the same font, colour, and style (e.g. bold, underline) PuTTY was using to display it.
This option can easily be inconvenient, so by default it is disabled.
4.13 The Colours panel
The Colours panel allows you to control PuTTY's use of colour.
4.13.1 ‘Allow terminal to specify ANSI colours’
This option is enabled by default. If it is disabled, PuTTY will ignore any control sequences sent by the server to request coloured text.
If you have a particularly garish application, you might want to turn this option off and make PuTTY only use the default foreground and background colours.
4.13.2 ‘Allow terminal to use xterm 256-colour mode’
This option is enabled by default. If it is disabled, PuTTY will ignore any control sequences sent by the server which use the extended 256-colour mode supported by recent versions of .
If you have an application which is supposed to use 256-colour mode and it isn't working, you may find you need to tell your server that your terminal supports 256 colours. On Unix, you do this by ensuring that the setting of describes a 256-colour-capable terminal. You can check this using a command such as :
If you do not see ‘’ in the output, you may need to change your terminal setting. On modern Linux machines, you could try ‘’.
4.13.3 ‘Allow terminal to use 24-bit colour’
This option is enabled by default. If it is disabled, PuTTY will ignore any control sequences sent by the server which use the control sequences supported by modern terminals to specify arbitrary 24-bit RGB colour value.
4.13.4 ‘Indicate bolded text by changing...’
When the server sends a control sequence indicating that some text should be displayed in bold, PuTTY can handle this in several ways. It can either change the font for a bold version, or use the same font in a brighter colour, or it can do both (brighten the colour and embolden the font). This control lets you choose which.
By default bold is indicated by colour, so non-bold text is displayed in light grey and bold text is displayed in bright white (and similarly in other colours). If you change the setting to ‘The font’ box, bold and non-bold text will be displayed in the same colour, and instead the font will change to indicate the difference. If you select ‘Both’, the font and the colour will both change.
Some applications rely on ‘bold black’ being distinguishable from a black background; if you choose ‘The font’, their text may become invisible.
4.13.5 ‘Attempt to use logical palettes’
Logical palettes are a mechanism by which a Windows application running on an 8-bit colour display can select precisely the colours it wants instead of going with the Windows standard defaults.
If you are not getting the colours you ask for on an 8-bit display, you can try enabling this option. However, be warned that it's never worked very well.
4.13.6 ‘Use system colours’
Enabling this option will cause PuTTY to ignore the configured colours for ‘Default Background/Foreground’ and ‘Cursor Colour/Text’ (see section 4.13.7), instead going with the system-wide defaults.
Note that non-bold and bold text will be the same colour if this option is enabled. You might want to change to indicating bold text by font changes (see section 4.13.4).
4.13.7 Adjusting the colours in the terminal window
The main colour control allows you to specify exactly what colours things should be displayed in. To modify one of the PuTTY colours, use the list box to select which colour you want to modify. The RGB values for that colour will appear on the right-hand side of the list box. Now, if you press the ‘Modify’ button, you will be presented with a colour selector, in which you can choose a new colour to go in place of the old one. (You may also edit the RGB values directly in the edit boxes, if you wish; each value is an integer from 0 to 255.)
PuTTY allows you to set the cursor colour, the default foreground and background, and the precise shades of all the ANSI configurable colours (black, red, green, yellow, blue, magenta, cyan, and white). You can also modify the precise shades used for the bold versions of these colours; these are used to display bold text if you have chosen to indicate that by colour (see section 4.13.4), and can also be used if the server asks specifically to use them. (Note that ‘Default Bold Background’ is not the background colour used for bold text; it is only used if the server specifically asks for a bold background.)
4.14 The Connection panel
The Connection panel allows you to configure options that apply to more than one type of connection.
4.14.1 Using keepalives to prevent disconnection
If you find your sessions are closing unexpectedly (most often with ‘Connection reset by peer’) after they have been idle for a while, you might want to try using this option.
Some network routers and firewalls need to keep track of all connections through them. Usually, these firewalls will assume a connection is dead if no data is transferred in either direction after a certain time interval. This can cause PuTTY sessions to be unexpectedly closed by the firewall if no traffic is seen in the session for some time.
Versions: 00
PKIX Working Group R. Housley (SPYRUS) Internet Draft W. Ford (NorTel) S. Farrell (SSE) D. Solo (BBN) expires in six months November 1995 Internet Public Key Infrastructuredraft-ietf-pkix-ipki-00.txt Status of this Memo This document is an Internet-Draft. Internet-Drafts are working documents of the Internet Engineering Task Force (IETF), its areas, and its working groups. Note that other groups may also distribute working documents as Internet-Drafts. Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet- Drafts as reference material or to cite them other than as ``work in progress.'' To learn the current status of any Internet-Draft, please check the ``1id-abstracts.txt'' listing contained in the Internet- Drafts Shadow Directories on ftp.is.co.za (Africa), nic.nordu.net (Europe), munnari.oz.au (Pacific Rim), ds.internic.net (US East Coast), or ftp.isi.edu (US West Coast). Abstract This is the first draft of the Internet Public Key Infrastructure. It is provided as a strawman for the first meeting of the PKIX Working Group. The intent of this strawman is to generate productive discussions at the first meeting. 1 Executive Summary << Write this last. >> 2 Requirements and Assumptions Goal is to develop a profile and associated management structure to facilitate the adoption/use of X.509 certificates within internet applications for those communities wishing to make use of X.509 Housley, Ford, Farrell, Solo [Page 1]
INTERNET DRAFT November 1995 technology. Such applications may include HTTP, electronic mail, IPSP, user authentication, electronic payment systems, as well as others. In order to relieve some of the obstacles to using X.509 certificates, this draft will define profiles, rules, and management protocols that should serve to promote the development of reusable certificate management systems; development of reusable application tools; and interoperabilty determined by policy, not syntax. Many communities will need to supplement, or possibly replace, this profile in order to meet the requirements of specialized domains or environments with additional authorization, assurance, or operational requirements. However, for basic applications, it is essential that a core of features be defined and that common means of representing common information be agreed to so that application developers can obtain necessary information without regard to the issuer of a particular certificate. As supplemental authorization and attribute management tools emerge, such as attribute certificates, it may be appropriate to limit what the certificate is used for in terms of conveying authenticated attributes as opposed to other means of conveying information. << Note, this section needs to be expanded >> 2.1 Communication and Topology The users of certificates will operate in a wide range of environments with respect to their communication topology, especially for secure electronic mail users. This profile will allow for users without high bandwidth, real-time IP connectivity, or high availablity of a connection. In addition, the profile must allow for the presence of firewall or other filtered communication. 2.2 Access Control and Acceptability Decisions The goal of the Public Key Infrstructure (PKI) is to meet the needs of deterministic, automated access control and authorization functions. This will drive the types of attributes and the nature of the identity contained in the certificate as well as the ancillary control information in the certificate such as policy data and certification path constraints. 2.3 User Expectations In this context, user refers to the users of the client software and the subjects of the certificates. These are the readers and writers of electronic mail, the clients for WWW browsers, etc. A goal of this profile is to recognize the limitations of both the platforms Housley, Ford, Farrell, Solo [Page 2]
INTERNET DRAFT November 1995 these users will employ and the sophistication/attentiveness of the users. This manifests itself in requirements to simplify the configuration responsibility of the user (e.g., root keys, rules), make platform usage constraints explicit in the certificate, to construct certification path constraints which shield the user from malicious action, and to construct applications which sensibly automate checking functions. 2.4 Administration Expectations As with users, the certificate profile should also be structured to be consistent with the types of individuals who must administer the CA space. Providing such an administrator with unbounded choices complicates not only the software that must process these certificates but also increases the chances that a subtle mistake by the CA administrator will result in broader compromise. 3 Overview of Approach3.1 X.509 Version 3 Certificate Application of public key technology requires the user of a public key to be confident that the public key belongs to the correct remote subject (person or system) with which an encryption or digital signature mechanism will be used. This confidence is obtained through the use of public key certificates, which are data structures that bind public key values to subject identities. The binding is achieved by having a trusted certification authority (CA) digitally sign each certificate. A certificate has a limited valid lifetime which is indicated in its signed contents. Because a certificate's signature and timeliness can be independently checked by a certificate-using client, certificates can be distributed via untrusted communications and server systems, and can be cached in unsecured storage in certificate-using systems. The standard known as ITU-T X.509 (formerly CCITT X.509) or ISO/IEC 9594-8, which was first published in 1988 as part of the X.500 Directory recommendations, defines a standard certificate format. The certificate format in the 1988 standard is called the version 1 (v1) format. When X.500 was revised in 1993, two more fields were added, resulting in the version 2 (v2) format. These two fields are used to support directory access control, and are not applicable to public key infrastructures. The Internet Privacy Enhanced Mail (PEM) proposals, published in 1993, included specifications for a public key infrastructure based on X.509 version 1 certificates [RFC 1422]. The experience gained in attempts to deploy RFC 1422 made it clear that the v1 and v2 Housley, Ford, Farrell, Solo [Page 3]
INTERNET DRAFT November 1995 certificate formats were deficient in several respects. Most importantly, more fields were needed to carry information which PEM design and implementation experience had proven necessary. In response to these new requirements, ISO/IEC and ANSI X9 developed the X.509 version 3 (v3) certificate format. The v3 format extends the v2 format by adding provision for additional extension fields. Particular extension field types may be specified in standards or may be defined and registered by any organization or community having a need. In August, 1995, standardization of the basic v3 format was completed [ISO TC]. ISO/IEC and ANSI X9 have also developed a set of standard extensions for use in the v3 extensions field [ISO DAM]. These extensions can convey such data as additional subject identification information, key attribute information, policy information, and certification path constraints. However, the ISO/IEC and ANSI standard extensions are very broad in their applicability. In order to develop interoperable implementations of X.509 v3 systems for Internet use, it is necessary to specify profiles of use of the X.509 v3 extensions tailored for the Internet. It is one goal of this document to specify such profiles. 3.2 Certification Paths and Trust A user of a security service requiring knowledge of a public key generally needs to obtain and validate a certificate containing the required public key. If the public-key user does not already hold an assured copy of the public key of the CA that signed the certificate, then it might need an additional certificate to obtain that public key. In general, a chain of multiple certificates may be needed, comprising a certificate of the public key owner (the end entity) signed by one CA, and zero or more additional certificates of CAs signed by other CAs. Such chains, called certification paths, are required because a public key user is only initialized with a limited number (often one) of assured CA public keys. There are different ways in which CAs might be configured in order for public key users to be able to find certification paths. For PEM, RFC 1422 defined a rigid hierarchical structure of CAs. There are three types of PEM certification authority: (a) Internet Policy Registration Authority (IPRA): This authority, operated under the auspices of the Internet Society, acts as the root of the PEM certification hierarchy at level 1. It issues certificates only for the next level of authorities, PCAs. All certification paths start with the IPRA. Housley, Ford, Farrell, Solo [Page 4]
INTERNET DRAFT November 1995 (b) Policy Certification Authorities (PCAs): PCAs are at level 2 of the hierarchy, each PCA being certified by the IPRA. A PCA must establish and publish a statement of its policy with respect to certifying users or subordinate certification authorities. Distinct PCAs aim to satisfy different user needs. For example, one PCA (an organizational PCA) might support the general electronic mail needs of commercial organizations, and another PCA (a high-assurance PCA) might have a more stringent policy designed for satisfying legally binding signature requirements. (c) Certification Authorities (CAs): CAs are at level 3 of the hierarchy and can also be at lower levels. Those at level 3 are certified by PCAs. CAs represent, for example, particular organizations, particular organizational units (e.g., departments, groups, sections), or particular geographical areas. RFC 1422 furthermore has a name subordination rule which requires that a CA can only issue certificates for entities whose names are subordinate (in the X.500 naming tree) to the name of the CA itself. The trust associated with a PEM certification path is implied by the PCA name. The name subordination rule ensures that CAs below the PCA are sensibly constrained as to the set of subordinate entities they can certify (e.g., a CA for an organization can only certify entities in that organization's name tree). Certificate user systems are able to mechanically check that the name subordination rule has been followed. The RFC 1422 CA hierarchical model has been found to have several deficiencies, including: (a) The pure top-down hierarchy, with all ertification paths starting from the root, is too restrictive for many purposes. For some applications, verification of certification paths should start with a public key of a CA in a user's own domain, rather than mandating that verification commence at the top of a hierarchy. In many environments, the local domain is often the most trusted. Also,initialization and key-pair-update operations can be more effectively conducted between an end entity and a local management system. (b) The name subordination rule introduces undesirable constraints upon the X.500 naming system an organization may use. (c) Use of the PCA concept requires knowledge of individual PCAs to be built into certificate chain verification logic. In the particular case of Internet mail, this is not a major problem -- the PCA name can always be displayed to the human user who can make a decision as to what trust to imply from a particular chain. However, Housley, Ford, Farrell, Solo [Page 5]
INTERNET DRAFT November 1995 in many commercial applications, such as electronic commerce or EDI, operator intervention to make policy decisions is impractical. The process needs to be automated to a much higher degree. In fact, the full process of certificate chain processing needs to be implementable in trusted software. Because of the above shortcomings, it is proposed that more flexible CA structures than the RFC 1422 hierarchy be supported by the PKIX specifications. In fact, the main reason for the structural restrictions imposed by RFC 1422 was the restricted certificate format provided with X.509 v1. With X.509 v3, most of the requirements addressed by RFC 1422 can be addressed using certificate extensions, without a need to restrict the CA structures used. In particular, the certificate extensions relating to certificate policies obviate the need for PCAs and the constraint extensions obviate the need for the name subordination rule. 3.3 Revocation When a certificate is issued, it is expected to be in use for its entire validity period. However, various circumstances may cause a certificate to become invalid prior to the expiration of the validity period. Such circumstances might include change of name, change of association between subject and CA (e.g., an employee terminates employment with an organization), and compromise or suspected compromise of the corresponding private key. Under such circumstances, the CA needs to revoke the certificate. X.509 defines one method of certificate revocation. This method involves each CA periodically issuing a signed data structure called a certificate revocation list (CRL). A CRL is a time stamped list identifying revoked certificates which is signed by a CA and made freely available in a public repository. Each revoked certificate is identified in a CRL by its certificate serial number. When a certificate-using system uses a certificate (e.g., for verifying a remote user's digital signature), that system not only checks the certificate signature and validity but also acquires a suitably- recent CRL and checks that the certificate serial number is not on that CRL. The meaning of "suitably-recent" may vary with local policy, but it usually means the most recently-issued CRL. A CA issues a new CRL on a regular periodic basis (e.g., hourly, daily, or weekly). Entries are added to CRLs as revocations occur, and an entry may be removed when the certificate expiration date is reached. An advantage of this revocation method is that CRLs may be distributed by exactly the same means as certificates themselves, namely, via untrusted communications and server systems. Housley, Ford, Farrell, Solo [Page 6]
INTERNET DRAFT November 1995 One limitation of the CRL revocation method, using untrusted communications and servers, is that the time granularity of revocation is limited to the CRL issue period. For example, if a revocation is reported now, that revocation will not be reliably notified to certificate-using systems until the next periodic CRL is issued -- this may be up to one hour, one day, or one week depending on the frequency that the CA issues CRLs. Another potential problem with CRLs is a risk of a CRL growing to an entirely unacceptable size. In the 1988 and 1993 versions of X.509, the CRL for the end-user certificates needed to cover the entire population of end-users for one CA. It is desirable to allow such populations to be in the range of thousands, tens of thousands, or possibly even hundreds of thousands of users. The end-user CRL is therefore at risk of growing to such sizes, which present major communication and storage overhead problems. With the version 2 CRL format, introduced along with the v3 certificate format, it becomes possible to arbitrarily divide the population of certificates for one CA into a number of partitions, each partition being associated with one CRL distribution point (e.g., directory entry or URL) from which CRLs are distributed. Therefore, the maximum CRL size can be controlled by a CA. Separate CRL distribution points can also exist for different revocation reasons. For example, routine revocations (e.g., name change) may be placed on a different CRL to revocations resulting from suspected key compromises, and policy may specify that the latter CRL be updated and issued more frequently than the former. As with the X.509 v3 certificate format, in order to facilitate interoperable implementations from multiple vendors, the X.509 v2 CRL format needs to be profiled for Internet use. It is one goal of this document to specify such profiles. Furthermore, it is recognized that on-line methods of revocation notification may be applicable in some environments as an alternative to the X.509 CRL. On-line revocation checking elimiates the latency between a revocation report and CRL the next issue. Once the revocation is reported, any query to the on- line service will correctly reflect the certificate validation impacts of the revocation. Therefore, this document will also consider standard approaches to on-line revocation notification. 3.4 Supporting Protocols Management protocols are required to support on-line interactions between Public Key Infrastructure (PKI) components. For example, management protocol might be used between a CA and a client system with which a key pair is associated, or between two CAs which cross- certify each other. The set of functions which potentially need to Housley, Ford, Farrell, Solo [Page 7]
INTERNET DRAFT November 1995 be supported by management protocols include: (a) registration: This is the process whereby a user first makes itself known to a CA, prior to that CA issuing a certificate or certificates for that user. (b) initialization: Before a client system can operate securely it is necessary to install in it necessary key materials which have the appropriate relationship with keys stored elsewhere in the infrastructure. For example, the client needs to be securely initialized with the public key of a CA, to be used in validating certificate paths. Furthermore, a client typically needs to be initialized with its own key pair(s). (c) certification: This is the process in which a CA issues a certificate for a user's public key, and returns that certificate to the user's client system and/or posts that certificate in a public repository. (d) key pair recovery: As an option, user client key materials (e.g., a user's private key used for encryption purposes) may be backed up by a CA or a key backup system associated with a CA. If a user needs to recover these backed up key materials (e.g., as a result of a forgotten password or a lost key chain file), an on-line protocol exchange may be needed to support such recovery. (e) key pair update: All key pairs need to be updated regularly, i.e., replaced with a new key pair, and new certificates issued. (f) revocation request: An authorized person advises a CA of an abnormal situation requiring certificate revocation. (g) cross-certification: Two CAs exchange the information necessary to establish cross-certificates between those CAs. Note that on-line protocols are not the only way of implementing the above functions. For all functions there are off-line methods of achieving the same result, and this specification does not mandate use of on- line protocols. For example, when hardware tokens are used, many of the functions may be achieved through as part of the physical token delivery. Furthermore, some of the above functions may be combined into one protocol exchange. In particular, two or more of the registration, initialization, and certification functions can be combined into one protocol exchange. Section 9 defines a set of standard protocols supporting the above functions. The protocols for conveying these exchanges in different environments (on-line, E-mail, and WWW) are specified in Section 10. Housley, Ford, Farrell, Solo [Page 8]
INTERNET DRAFT November 19954 Certificate and Certificate Extensions Profile As described above, one goal of this draft is to create a profile for X.509 v3 certificates that will foster interoperability and a reusable public key infrastructure. To achieve this goal, some assumptions need to be made about the nature of information to be included along with guidelines for how extensibility will be employed. Certificates may be used in a wide range of applications and environments covering a broad spectrum of interoperability goals and a broader spectrum of operational and assurance requirements. The goal of this draft is to establish a common baseline for generic applications requiring broad interoperability and limited special purpose requirements. In particular, the emphasis will be on supporting the use of X.509 v3 certificates for informal internet electronic mail, IPSEC, and WWW applications. The draft will define a baseline set of information along with common locations within a certificate and common representations for common information. Environments with additional requirements may build on this profile or may replace it. 4.1 Basic Certificate Fields The X.509 v3 certificate Basic syntax is as follows. For signature calculation, the certificate is ASN.1 DER encoded (reference). ASN.1 DER encoding is a tag, length, value encoding system for each element. Certificate ::= SIGNED { SEQUENCE { version [0] Version DEFAULT v1, serialNumber CertificateSerialNumber, signature AlgorithmIdentifier, issuer Name, validity Validity, subject Name, subjectPublicKeyInfo SubjectPublicKeyInfo, issuerUniqueID [1] IMPLICIT UniqueIdentifier OPTIONAL, -- If present, version must be v2 or v3 subjectUniqueID [2] IMPLICIT UniqueIdentifier OPTIONAL, -- If present, version must be v2 or v3 extensions [3] Extensions OPTIONAL -- If present, version must be v3 } } Version ::= INTEGER { v1(0), v2(1), v3(2) } CertificateSerialNumber ::= INTEGER Housley, Ford, Farrell, Solo [Page 9]
INTERNET DRAFT November 1995 Validity ::= SEQUENCE { notBefore UTCTime, notAfter UTCTime } UniqueIdentifier ::= BIT STRING SubjectPublicKeyInfo ::= SEQUENCE { algorithm AlgorithmIdentifier, subjectPublicKey BIT STRING } The following items describe a proposed use of the X.509 v3 certificate for the Internet. 4.1.1 Version This field describes the version of the encoded certificate. When extensions are used, as expected in this profile, use X.509 version 3 (value is 2). If no extensions are present, but a UniqueID is present, use version 2 (value is 1). If only basic fields are present, use version 1 (the value is omitted from the certificate as the default value). << All capabilites available in X.509 v2 certificates are available in X.509 v3 certificates. Since there are so few X.509 v2 certificate implementations, should the profile prohibit the use of v2? >> 4.1.2 Serial number The serial number is an integer assigned by the certification authority to each certificate. It must be unique for each certificate issued by a given CA (i.e., the issuer name and serial number identify a unique certificate). << Do we want to define a maximum value for the serial number? >> 4.1.3 Signature This field contains the algorithm identifier for the algorithm used to sign the certificate. 4.1.4 Issuer Name The issuer name provides a globally unique identifier of the authority signing the certificate. The syntax of the issuer name is an X.500 distinguished name. A name in the certificate may provide semantic information, may provide a reference to an external information store or service, provides a unique identifier, may Housley, Ford, Farrell, Solo [Page 10]
INTERNET DRAFT November 1995 provide authorization information, or may provide a basis for managing the CA relationships and certificate paths (other purposes are also possible). This strawman suggests that the issuer (and subject) name fields must provide a globally unique identifier. In addition, they should contain semantic information identifying the issuer/subject (e.g. a full name, organization name, etc.). Access information will be provided in a separate extension (when other than via X.500 directory) and internet specific identities (electronic mail address, DNS name, and URLs) will be carried in alternative name extensions. << Further discussion of naming guidelines for internet use is needed. >> 4.1.5 Validity This field indicates the dates on which the certificate becomes valid (notBefore) and on which the certificate ceases to be valid (notAfter). 4.1.6 Subject Name The purpose of the subject name is to provide a unique identifier of the subject of the certificate. The syntax of the subject name is an X.500 distinguished name. The discussion in section 4.1.4 on issuer names applies to subject names as well. 4.1.7 Subject Public Key Info This field is used to carry the public key and identify the algorithm with which the key is used. 4.1.8 Unique Identifiers The subject and issuer unique identifier are present in the certificate to handle the possibility of reuse of subject and/or issuer names over time. Based on the approach to naming, names will not be reused and internet certificates will not make use of these unique identifiers. 4.2 Certificate Extensions The extensions already defined by ANSI X9 and ISO for X.509 v3 certificates provide methods for associating additional attributes with users or public keys and for managing the certification hierarchy. The X.509 v3 certificate format also allows communities to define private extensions to carry information unique to those communities. Each extension in a certificate may be designated as Housley, Ford, Farrell, Solo [Page 11]
INTERNET DRAFT November 1995 critical or non-critical. A certificate using system (an application validating a certificate) must reject the certificate if it encounters a critical extension it does not recognize. A non- critical extension may be ignored if it is not recognized. The following presents recommended extensions used within Internet certificates and standard locations for information. Communities may elect to use additional extensions; however, caution should be exercised in adopting any critical extensions in certificates which might be used in a general context. 4.2.1 Subject Alternative Name The altNames extension allows additional identities to be bound to the subject of the certificate. Defined options include an rfc822 name (electronic mail address), a DNS name, and a URL. Each of these are IA5 strings. Multiple instances may be included. Whenever such identities are to be bound in a certificate, the subject alternative name (or issuer alternative name) field shall be used. << This implies that encoding of such identities within the subject or issuer distinguished name is discouraged. >> << Note definition is based on a recommended change to the DAM. >> AltNames ::= SEQUENCE OF GeneralName GeneralName ::= CHOICE { otherName [0] INSTANCE OF OTHER-NAME, rfc822Name [1] IA5String, dNSName [2] IA5String, x400Address [3] ORAddress, directoryName [4] Name, ediPartyName [5] IA5String, url [6] IA5String } << Should we permit an IP address? With the current list of choices, IPSec would use dnsName. This leads to trusted resolution of DNS Names to IP Addresses which is not done today. Maybe IP address is too specific and LAN address should be allowed too. >> 4.2.2 Issuer Alternative Name As with 4.2.1, this extension is used to bind Internet style identities to the issuer name. Housley, Ford, Farrell, Solo [Page 12]
INTERNET DRAFT November 19954.2.3 Certificate Policies The certificatePolicies extension contains an object identifier (OID) which indicates the policy under which the certificate has been issued. Use of policies is discussed elsewhere in this draft. 4.2.4 Key Attributes The keyAttributes extension contains information about the key itself including a unique key identifier, a key usage period (lifetime of the key as opposed to the lifetime of the certificate), and key usage. The Internet certificate should use the keyAttributes extension and contain a key identifier and private key validity to aid in system management. The key usage field in this extension is intended to be advisory (as contrasted with the key usage restriction extension which imposes mandatory restrictions). The key usage field in this extension should not be used. KeyAttributes ::= SEQUENCE { keyIdentifier KeyIdentifier OPTIONAL, intendedKeyUsage KeyUsage OPTIONAL, privateKeyUsagePeriod PrivateKeyValidity OPTIONAL } KeyIdentifier ::= OCTET STRING PrivateKeyValidity ::= SEQUENCE { notBefore [0] GeneralizedTime OPTIONAL, notAfter [1] GeneralizedTime OPTIONAL } KeyUsage ::= BIT STRING { digitalSignature (0), nonRepudiation (1), keyEncipherment (2), dataEncipherment (3), keyAgreement (4), keyCertSign (5), offLineCRLSign (6) } 4.2.5 Key Usage Restriction The keyUsageRestriction extension defines mandatory restrictions on the use of the key contained in the certificate based on policy and/or usage (e.g., signature, encryption). This field should be used whenever the use of the key is to be restricted based on either usage or policy (see discussion in policies). The usage restriction would be employed when a multipurpose key is to be restricted (e.g., when an RSA key should be used only for signing or only for key encipherment). Housley, Ford, Farrell, Solo [Page 13]
INTERNET DRAFT November 1995 keyUsageRestriction ::= SEQUENCE { certPolicySet SEQUENCE OF CertPolicyId OPTIONAL, restrictedKeyUsage KeyUsage OPTIONAL } 4.2.6 Basic Constraints The basicConstraints extension identifies whether the subject of the certificate is a CA or an end user. In addition, this field can limit the authority of the CA in terms of the certificates it can issue. Discussion of certification path restriction is covered elsewhere in this draft. The subject type field should be present in all Internet certificates. basicConstraints ::= SEQUENCE { subjectType SubjectType, pathLenConstraint INTEGER OPTIONAL, permittedSubtrees SEQUENCE OF GeneralName OPTIONAL, excludedSubtrees SEQUENCE OF GeneralName OPTIONAL } SubjectType ::= BIT STRING { cA (0), endEntity (1) } 4.2.7 CRL Distribution Points The cRLDistributionPoints extension identifies the CRL distribution point or points to which a certificate user should refer to acertain if the certificate has been revoked. This extenstion provides a mechanism to divide the CRL inot manageable pieces if the CA has a large constituency. << Need a section which discusses the alternatives. Should permit URLs as one method to name the location for the most recent CRL. >> 4.2.8 Information Access The informationAccess field is proposed as a private extension to tell how information about a subject or CA (or ancillary CA services) may be accessed. For example, this field might provide a pointer to information about a user (e.g., a URL) or might tell how to access CA information such as certificate status or on-line validation services. The structure of this extension is TBD. << Suggestions on the ASN.1 syntax are welcome. >> Housley, Ford, Farrell, Solo [Page 14]
INTERNET DRAFT November 19954.2.9 Other extensions The DAM defines additional extensions; however, this draft does not include them as there use is not part of the basic Internet profile. 4.3 Examples << Certificate samples including descriptive text and ASN.1 encoded blobs will be inserted. >> 5 CRL and CRL Extensions Profile As described above, one goal of this draft is to create a profile for X.509 v2 CRLs that will foster interoperability and a reusable public key infrastructure. To achieve this goal, some assumptions need to be made about the nature of information to be included along with guidelines for how extensibility will be employed. CRLs may be used in a wide range of applications and environments covering a broad spectrum of interoperability goals and a broader spectrum of operational and assurance requirements. The goal of this draft is to establish a common baseline for generic applications requiring broad interoperability and limited special purpose requirements. Emphasis will be on support for X.509 v2 CRLs. The draft will define a baseline set of information along with common locations within a CRL and common representations for common information. Environments with additional requirements may build on this profile or may replace it. 5.1 CRL Fields The X.509 v2 CRL syntax is as follows. For signature calculation, the data that is to be signed is ASN.1 DER encoded. ASN.1 DER encoding is a tag, length, value encoding system for each element. CertificateList ::= SIGNED SEQUENCE { version Version DEFAULT v1, signature AlgorithmIdentifier, issuer Name, lastUpdate UTCTime, nextUpdate UTCTime, revokedCertificates SIGNED SEQUENCE OF SEQUENCE { signature AlgorithmIdentifier, issuer Name, userCertificate SerialNumber, revocationDate UTCTime, crlEntryExtensions Extensions OPTIONAL } OPTIONAL, crlExtensions [0] Extensions OPTIONAL } } Housley, Ford, Farrell, Solo [Page 15]
INTERNET DRAFT November 1995 Version ::= INTEGER { v1(0), v2(1) } SerialNumber ::= INTEGER The following items describe a proposed use of the X.509 v2 CRL for the Internet. 5.1.1 Version This field describes the version of the encoded CRL. When extensions are used, as expected in this profile, use version 2 (value is 1). If neither CRL extensions nor CRL entry extensions are present, use version 1 (the value is omitted). 5.1.2 Signature This field contains the algorithm identifier for the algorithm used to sign the CRL. 5.1.3 Issuer Name The issuer name provides a globally unique identifier of the certification authority signing the CRL. The syntax of the issuer name is an X.500 distinguished name. This strawman suggests that the issuer name must provide a globally unique identifier. In addition, it should contain semantic information identifying the certification authority. << Any changes to 4.1.4 must be reflected here too. >> 5.1.4 Last Update This field indicates the date on which this CRL was issued. 5.1.5 Next Update This field indicates the date by which the next CRL will be issued. The next CRL could be issued before the indicated date, but it will not be issued any later than the indicated date. 5.1.6 Revoked Certificates Revoked certificates are listed. The certificates are named by the combination of the issuer name and the user certificate serial number. The date on which the revocation occured is specified. Each revocation entry is individually signed. This profile mandates the use of same signature algorithm to sign each CRL entry and the whole CRL. CRL entry extensions are discussed in section 5.3. Housley, Ford, Farrell, Solo [Page 16]
INTERNET DRAFT November 19955.2 CRL Extensions The extensions already defined by ANSI X9 and ISO for X.509 v2 CRLs provide methods for associating additional attributes with CRLs. The X.509 v2 CRL format also allows communities to define private extensions to carry information unique to those communities. Each extension in a CRL may be designated as critical or non-critical. A CRL validation must fail if it encounters an critical extension. However, an unrecognized non-critical extension may be ignored. The following presents recommended extensions used within Internet CRLs and standard locations for information. Communities may elect to use additional extensions; however, caution should be exercised in adopting any critical extensions in CRLs which might be used in a general context. 5.2.1 Authority Key Identifier The authorityKeyIdentifier is a non-critical CRL extension that allows the CA to include an identifier of the key used to sign the CRL. This extension is useful when a CA uses more than one key. See section 7 for a discussion key changeover. AuthorityKeyId ::= SEQUENCE { keyIdentifier [0] KeyIdentifier OPTIONAL, certIssuer [1] Name OPTIONAL, certSerialNumber [2] CertificateSerialNumber OPTIONAL } ( CONSTRAINED BY { -- certIssuer and certSerialNumber constitute a logical pair, -- and if either is present both must be present. Either this -- pair or the keyIdentifier field or all shall be present. -- } ) 5.2.2 Issuer Alternative Name The issuerAltName is a non-critical CRL extension that provides a CA name, in a form other than an X.500 distinguished name. The syntax for the issuerAltName is the same as described in section 4.2.1. Each of the alternate names is an IA5 string. Multiple instances may be included. Whenever such alternative names are included in a CRL, the issuer alternative name field shall be used. 5.2.3 CRL Number The cRLNumber is a non-critical CRL extension which conveys a monotonically increacing sequence number for each CRL issued by a given CA through a given CA X.500 Directory entry or CRL distribution point. This extension allows users to easily determine is a particular CRL superceeds another CRL. Use of this CRL extension is strongly encouraged. Housley, Ford, Farrell, Solo [Page 17]
INTERNET DRAFT November 1995 CRLNumber ::= INTEGER 5.2.4 Issuing Distribution Point The issuingDistributionPoint is a critical CRL extension that identifiers the CRL distribution point for this particular CRL, and it indicates whether the CRL covers revocation for end entities certificate only, CA certificates only, or a limitied set of reason codes. Support for CRL distribution points is strongly encouraged. However, the use of certificateHold is strongly discouraged. DistributionPoint ::= SEQUENCE { distributionPoint DistributionPointName, reasons ReasonFlags OPTIONAL } DistributionPointName ::= CHOICE { fullName [0] Name, nameRelativeToCA [1] RelativeDistinguishedName } ReasonFlags ::= BIT STRING { unused (0), keyCompromise (1), caCompromise (2), affiliationChanged (3), superseded (4), cessationOfOperation (5), certificateHold (6) } 5.2.5 Delta CRL Indicator The deltaCRLIndicator is a critical CRL extension that identifies a delta-CRL. The use of delta-CRLs is strongly discouraged. Rather, CAs are encouraged to always issue complete CRLs. 5.3 CRL Entry Extensions The CRL entry extensions already defined by ANSI X9 and ISO for X.509 v2 CRLs provide methods for associating additional attributes with CRL entries. The X.509 v2 CRL format also allows communities to define private CRL entry extensions to carry information unique to those communities. Each extension in a CRL entry may be designated as critical or non-critical. A CRL validation must fail if it encounters an critical CRL entry extension. However, an unrecognized non-critical CRL entry extension may be ignored. The following presents recommended extensions used within Internet CRL entries and standard locations for information. Communities may elect to use additional CRL entry extensions; however, caution should be exercised in adopting any critical extensions in CRL entries which might be Housley, Ford, Farrell, Solo [Page 18]
INTERNET DRAFT November 1995 used in a general context. 5.3.1 Reason Code The reasonCode is a non-critical CRL entry extension that identifies the reason for the certificate revocation. The inclusion of reason codes is encouraged. The reasonCode extension permits certificates to placed on hold or suspended. The processing associated with suspended certificates greatly complicates certificate validation. The use of this feature is strongly discouraged. CRLReason ::= ENUMERATED { unspecified (0), keyCompromise (1), caCompromise (2), affiliationChanged (3), superseded (4), cessationOfOperation (5), certificateHold (6), certHoldRelease (7), removeFromCRL (8) } 5.3.2 Expiration Date The expirationDate is a non-critical CRL entry extension that indicates the expiration of a hold entry in a CRL. The use of this extension is strongly discouraged. 5.3.3 Instruction Code The instructionCode is a non-critical CRL entry extension that provides a registered instruction identifier which indicates the action to be taken after encountering a certificate that has been placed on hold. The use of this extension is strongly discouraged. 5.3.4 Invalidity Date The invalidityDate is a non-critical CRL entry extension that provides the date on which it is known or suspected that the private key was compromised or that the certificate otherwise became invalid. This date may be earlier than the revocation date in the CRL entry (which is the date that the CA revoked the certificate). The use of this extension is encouraged. InvalidityDate ::= GeneralizedTime Housley, Ford, Farrell, Solo [Page 19]
INTERNET DRAFT November 19955.4 Examples << CRL samples including descriptive text and ASN.1 encoded blobs will be inserted. >> 6 Certificate and CRL Distribution6.1 Distribution via X.500 Within an X.500 Directory, the certificate for an end entity can be found in the userCertificate attribute. This attribute is normally associated with the strongAuthenticationUser object class. Within an X.500 Directory, the certificate for a certification authority can be found in the cACertificate attribute, and the most recent CRL can be found in the certificateRevocationList attribute. These attributes are normally associated with the certificationAuthority object class. 6.2 Distribution via Electronic MailRFC 1424 specifies methods for key certification, certificate revocation list (CRL) storage, and CRL retrieval. These services are required of an RFC 1422 certification authority. Each service involves an electronic mail request and an electronic mail reply. << Need to define a format for one user to send his certificate to another. This format could be used to obtain arbitrary certificates from a certificate server or to solicit certificates from the user themselves. >> 6.3 Distribution via HTTP << Need to define a convention for using HTTP to obtain certificates from a server. >> As discussed in section 4.2.7, the user certificate may contain a URL that specifies the location where the most recent CRL which could contain an entry revoking the certificate can be found. HTTP can be used to fetch the most recent CRL from this location. 6.4 On-line Certificate Validation As discussed above, consumers of certificates must be able to determine the validity of a certificate when using the certificate. There are many possible approaches to informing consumers on the status of the certificate and these approaches have different operational characteristics. One alternative is to provide an on- Housley, Ford, Farrell, Solo [Page 20]
INTERNET DRAFT November 1995 line validation service. Such a service reduces the complexity of the client applications (by moving it to the on-line service), and it provides the most timely status possible. In addition, on-line validation servers can also help to resolve the root key management a distribution problem by providing a single trusted agent for asserting root key status where the agent is independent of the certification hierarchy itself. The on-line validation could be performed by either the CA who issued the certificate (directly or via a delegatee) or as a general service by a "trusted" third party. Note, this service could also be extended to the validation of any certificate like item (e.g., PGP credential, DNS record, STT credential) and could facilitate application interaction between users using different certificate formats. The general model involves a request/response format which might be transferred using a number of alternative transport protocols. In general, the requestor sends the certificate (or a user reference) along with an indication of the service to be provided. This service might be coupled with the general certificate distribution service by adding service flags to that request as well. The request should contain: << this section is still in progress >> Certificate (or cert path) Service parameters Parse cert for me Check CRLs Result format (ASN, Text, HTML, ....) Sign result (with a specified algorithm) Other qualifiers Desired domain/policy OID (does this validate to a specific Root) A possible Syntax: ValidationRequest ::= SEQUENCE { CertPathType OBJECT IDENTIFIER, CertPath SEQUENCE OF OCTET STRING, TargetRootID Name OPTIONAL, ServiceParams SEQUENCE OF ServiceParam OPTIONAL } ServiceParam ::= INTEGER { ASNresult (1), Textresult (2), HTMLresult (3), .... } Housley, Ford, Farrell, Solo [Page 21]
INTERNET DRAFT November 1995 The response should contain: Status: current/valid, expired (date), revoked (date/reason), suspended Cert path problem: what failed, where, and why Policy/attribute/constraints from validated cert path Parsed data: name, key, attributes Could be signed by validator or rely on secure channel A possible syntax: ValidationResponse ::= OPTIONALLY SIGNED SEQUENCE { validator Name OPTIONAL, certInfo CHOICE { cert OCTET STRING, reference IssuerSerial, certdata T61 STRING }, -- text including name, key, and attributes status StatusCode, detail ANY Defined By StatusCode OPTIONAL, validationData ???? } -- problems with cert path, policy attributes, etc. StatusCode ::= INTEGER { valid (1), revoked (2), expired (3), suspended (4) } 7 Key Pair Updating Procedures A fundamental principle of the PKI is that it must be possible to update all of the cryptographic keys used, both by end entity's and by PKI components (e.g., CAs). Furthermore, for the PKI to be usable, the update of one key pair must not force the update of any other key pair or Certificate. In this section, we deal with the update of CA key pairs. Key updating for end entities is dealt with in section 9.4. For CA key pair updating we will fulfil the following requirements: (a) All certificates valid before the update must remain valid. (b) A subject whose certificate is verifiable using the new CA public key must also be able to verify certificates verifiable using the old public key. (c) End entities who directly trust the old CA key pair must be able to verify certificates signed using the new key CA private key. This Housley, Ford, Farrell, Solo [Page 22]
INTERNET DRAFT November 1995 is required for situations where the old CA public key is "hardwired" into the end entity's cryptographic equipment (e.g., smartcard memory). (d) All entities (not just those certified by that CA) must have both the new and old CA public keys available from the time of the change (whether or not they trust it is a local matter). The basis of the scheme described below is that the CA protects its new public key using its previous private key and vice-versa. Thus when a CA updates its key pair it must generate two new cACertificate attribute values if certificates are made available using an X.500 directory. Note that the scheme below does not make use of any of the X.509 v3 certificate extensions as it must be able to work for X.509 v1 certificates. However, the presence of the KeyIdentifier extension permits efficiency improvements. Note that the change of a CA key affects both certificate verification and CRL checking. It is worth noting that the operation involved here is key update, only the key pair (and related attributes) of the CA are changed. Thus, this operation cannot be used in the event of a CA key compromise. While the scheme could be generalised to cover cases where the CA updates its key pair more than once during the validity period of one of its end entity's certificates, this generalisation seems of dubious value. Therefore, the validity period of a CA key must be greater than the validity period of any certificate issued by that CA. We first present the data structures required then specify the steps involved in changing the CA key and the various possibilities for certificate verification. Note that the description below assumes that X.500 is used for publishing certificates. This assumption is simply for clarity of presentation, if the same data structures are published some other way, the scheme still works. 7.1 ASN.1 Data Types -- existing CA cert from X.509 -- this contains the current and old CA certificate(s) -- all entities under this CA need a local copy of -- one of these CACertificate ::= ATTRIBUTE Housley, Ford, Farrell, Solo [Page 23]
INTERNET DRAFT November 1995 WITH ATTRIBUTE-SYNTAX Certificate -- Securing the old CA public key with the new private key and -- vice-versa. Securing the new CA public key with the old private -- key is needed to avoid having to issue the new CA public key -- using out-of-band means to entities certified using the old CA -- key; with this they can verify certificates signed using the new -- CA private key. -- The data structures can be stored in this X.500 attribute CALinkages ::= ATTRIBUTE WITH ATTRIBUTE-SYNTAX CALinkage CALinkage ::= SIGNED SEQUENCE { protectedCACertSerial INTEGER, -- the serial number in the CACertificate -- value which we wish to link to protectingCACertSerial INTEGER, -- the serial number in the CACertificate -- value which contains the public key -- corresponding to the private key used -- to sign this caName Name, link HASH Certificate } 7.2 CA Operator Actions To change the key of the CA, the CA operator does the following: (1) Generates a new key pair. (2) Calculate the certificate for the new key pair. (3) Create a CALinkage (based on the old CA certificate) using the new private key. (4) Create a CALinkage (based on the new CA certificate) using the old private key. (5) Publish these new data structures. 7.3 Verifying Certificates Normally when verifying a signature, the verifier simply verifies the certificate containing the public key of the signer. However, once a CA is allowed to update it's key there are a range of new possibilities. These are shown in the table below. The term PSE (personal security environment) is used to denote Housley, Ford, Farrell, Solo [Page 24]
INTERNET DRAFT November 1995 locally held and trusted information. This can only be assumed to include a single CA public key. Signer's Case 2: Case 4: Case 6: Case 8: cert is In this In this case The verifier Although the protected case the the verifier thinks this CA operator using OLD verifier can directly is the has not public must access verify the situation of updated the key the certificate case 2 and directory, the directory without will access verifier can in order to using the the verify the get the directory directory, certificate value of however the directly -- the OLD verification this is thus public key will FAIL the same as case 4. 7.3.1 Verification in cases 1, 4, 5 and 8 In these cases the verifier has a local copy of the CA public key which can be used to verify the certificate directly. This is the same as the situation where no key change has ever occurred. Note that case 8 may arise between the time when the CA operator has generated the new key pair and the time when the CA operator stores the updated attributes in the Directory. Case 5 can only arise if the CA operator has issued both the signer's and verifier's Housley, Ford, Farrell, Solo [Page 25]
INTERNET DRAFT November 1995 certificates during this "gap" (the CA operator should avoid this as it leads to the failure cases described below). 7.3.2 Verification in case 2 In case 2 the verifier must get access to the old public key of the CA. The verifier does the following: (1) Lookup the CACertificate attribute in the directory and pick the appropriate value. (2) Lookup the associated CALinkages attribute value. (3) Verify that these are correct using the new CA key (which the verifier has locally). (4) If correct then check the signer's certificate using the old CA key. Case 2 will arise when the CA operator has issued the signer's certificate, then changed key and then issued the verifier's certificate, so it is quite a typical case. 7.3.3 Verification in case 3 In case 3 the verifier must get access to the new public key of the CA. The verifier does the following: (1) Lookup the CACertificate attribute in the directory and pick the appropriate value. (2) Lookup the associated CALinkages attribute value. (3) Verify that these are correct using the old CA key (which the verifier has stored locally). (4) If correct then check the signer's certificate using the new CA key. Case 3 will arise when the CA operator has issued the verifier's certificate, then changed key and then issued the signer's certificate, so it is also quite a typical case. 7.3.4 Failure of verification in case 6 In this case, the CA has issued the verifier's PSE containing the new key without updating the directory attributes. This means that the verifier has no means to get a trustworthy version of the CA's old Housley, Ford, Farrell, Solo [Page 26]
INTERNET DRAFT November 1995 key and so verification fails. Note that the failure is the CA operator's fault. 7.3.5 Failure of verification in case 7 In this case the CA has issued the signer's certificate protected with the new key without updating the directory attributes. This means that the verifier has no means to get a trustworthy version of the CA's new key and so verification fails. Note that the failure is the CA operator's fault. 7.4 Revocation - Change of CA Key As we saw above, the verification of a certificate becomes more complex once the CA is allowed to change its key. This is also true for revocation checks as the CA may have signed the CRL using a newer private key than the one within the user's PSE. The analysis of the alternatives is exactly as for certificate verification. 8 Guidelines for Certificate Policy Definition << To Be Decided >> 9 Supporting Management Protocols The certificate management protocol exchanges defined in this section support management communications between client systems, each of which supports one or more users, and CAs. In addition, one management protocol exchange is defined for use between two CAs, for the purpose of establishing cross-certificates. Each exchange is defined in terms of a sequence of messages between the two systems concerned. This section defines the contents of the messages exchanged. The protocols for conveying these exchanges in different environments (on-line, E-mail, and WWW) are specified in Section 10. The protocol exchanges defined in this document are: - One-Step Registration/Certification - User Registration - User Initialization/Certification with Client-Generated Encryption Key Pair - User Initialization/Certification with Centrally-Generated Encryption Key Pair - Encryption Key Pair Recovery Housley, Ford, Farrell, Solo [Page 27]
INTERNET DRAFT November 1995 - Key Pair Update for Client-Generated Key Pair - Key Pair Update for Centrally-Generated Key Pair - Key Pair Update (Centrally-Initiated) - Revocation Request - Cross-Certification The following notes apply to the protocol exchange descriptions: - In exchanges between a client system and a CA, the protocol exchange is initiated by the client system. The one exception to this is the Key Pair Update (Centrally-Initiated) exchange. - To provide an upgrade path, a protocol version indicator is always included in the first message of an exchange. - A message type indicator is included in the protected part of all messages. - All messages include an optional transaction identifier which is used to assist correlation of request and response messages for one transaction. This identifier is generated by the initiator of the exchange and will typically include the initiator's name plus a transaction sequence number. - The initial message from the client to the CA may optionally contain the client system time. This is used to facilitate the correction of client time problems by central administrators. - Responses from CA to client include the CA system time. The client can use this time to check that its own system time is within a reasonable range. - Random numbers are used in some of the protocols to prevent replay of the exchanges. - Responses can be aborted at any time. An enumerated error code is sent from the aborting end and can be decoded into a user readable error string at the other end. Error codes are not specified in this version of this document. - Items in square brackets [] are optional. - In every instance in which a public key is transferred, it is transferred in the form of X.509 subjectPublicKeyInfo, including algorithm identifier and (optional) parameters. - When a new key pair is generated by a client, a key identifier may optionally be sent to the CA along with the public key for inclusion in the certificate. However, the CA may override this value with a key identifier of its own. If the client is concerned about the key identifier value used, it should check the new certificate. - Where this description refers to an encryption key pair, this could be a key pair for RSA key transport or could be key pair for key establishment using, for example, a Diffie-Hellman based algorithm. Note that in this version of this document, the message contents are defined at an outline level only. A future version of this document will fill out the full details of message syntax in ASN.1. Housley, Ford, Farrell, Solo [Page 28]
INTERNET DRAFT November 19959.1 One-Step Registration/Certification9.1.1 Overview of Exchange This protocol exchange is used to support registration of a user, together with request and issue of certificate(s), for use in environments in which client systems generate their own key pair or pairs. It is a simple exchange, designed for easy implementation, but lacks some of the features and protective measures inherent in the exchanges defined subsequently. The user must have a pre-established digital signature key pair. Furthermore, the user must have a preestablished reliably-known copy of the public key of the CA concerned (this generally requires some form of off-line data exchange to ensure that the correct public key is known). If the request is accepted by the CA, it results in the generation of certificate(s) for client-generated digital signature and/or encryption public keys. 9.1.2 Detailed Description A single message is used for a user to register with a CA and request certificate issuance. RegCertRequest:: client-to-CA { protocol version message type [transaction identifier] [client system time] user unique name (DN) [user signature public key] [user signature key identifier] [client-generated encryption public key] [client-generated encryption key identifier] user attributes [certificate policy] } Signature (signed with user signature private key) No specific message is defined to return the generated certificate(s). It is assumed that the client will obtain a copy of the certificate(s) by other means and, by checking the certificate contents and CA signature, ensure that the request was processed by the correct CA. Housley, Ford, Farrell, Solo [Page 29]
INTERNET DRAFT November 19959.2 User Registration9.2.1 Overview of Exchange This protocol exchange is used for a user to request registration with a CA. It is a first step in the establishment of key materials and certificates between client and CA for that user. Assuming the CA accepts the request, it will be necessary to follow-up this exchange with a User Initialization/Certification exchange as described in 9.3 or 9.4. At the time this request is issued, it is not necessary for the client to have any established key materials. 9.2.2 Detailed Description A single message is used for a user to request registration with a CA. RegisterUserRequest:: client-to-CA { protocol version message type [transaction identifier] [client system time] user unique name (DN) user attributes [certificate policy] } Signature (signed with user signature private key) No specific message is defined to respond to this request. It is asumed that the procedure defined in 9.3 or 9.4 will follow. 9.3 User Initialization/Certification with Client-Generated Encryption Key Pair 9.3.1 Overview of Exchange This protocol exchange is used to support client initialization, including certificate issuance, for one user, with provision for simultaneously establishing and certifying separate key pairs for digital signature and encryption (or encryption key exchange) purposes. Both key pairs are generated by the client and no private key is exposed to the CA. Generation and certification of the encryption key pair is optional. Prior to conducting this exchange, the user must have registered with the CA, either using the user registration exchange defined in 9.2 or by other means. Housley, Ford, Farrell, Solo [Page 30]
INTERNET DRAFT November 1995 Following registration, the CA creates a secret data item, called an authorization code, and transfers this data item by out-of-band means to the user. The authorization code is used to establish authentication and integrity protection of the user initialization/certification on-line exchange. This is done by generating a symmetric key based on the authorization code and using this symmetric key for generating Message Authentication Codes (MACs) on all exchanges between client and CA. In the first two messages exchanged, the client sends its user signature public key (and, optionally, a client-generated encryption public key) to the CA and the CA returns the currently valid CA certificate(s). This exchange of public keys allows the client and CA to authenticate each other. 9.3.2 Detailed Description The user receives a reference number and a secret machine-generated authorization code from the CA administrator. Both pieces of information are transferred to the user in a secure manner which preserves their integrity and confidentiality. The reference number is used to uniquely identify the client at the CA and the authorization code is used to secure the exchange integrity-wise. The reference number is used instead of a DN to uniquely identify the client because a DN may be lengthy and difficult for a user to manually type without error. After the reference number and authorization code have been entered by the user, the client generates: - a client random number, - (if a new user signature key pair is required) a new user signature key pair, - (if a new client-generated encryption key pair is required) a new encryption key pair. The client securely stores locally any new signature private key and/or client-generated encryption private key. The client then sends the message InitClientRequest to the CA. The entire structure is protected from modification with a MAC based on the authorization code. InitClientRequest:: client-to-CA { protocol version message type [transaction identifier] [client system time] Housley, Ford, Farrell, Solo [Page 31]
INTERNET DRAFT November 1995 client random number reference number user signature public key [user signature key id] [client-generated encryption public key] [client-generated encryption key id] MAC algorithm id } MAC (key based on authorization code) Upon receipt of the InitClientRequest structure, if the CA recognizes the reference number and if the protocol version is valid, it saves the client random number, generates its own random number (CA random number), and validates the MAC. Then for the user encryption public key, it creates: - a new certificate for the user?s digital signature public key, - (if a new client-generated encryption key pair is required) a new certificate. The CA responds to the client with the message InitClientResponse. The entire structure is protected from modification with a MAC based on the authorization code. InitClientResponse:: CA-to-client { message type [transaction identifier] client random number CA random number CA signature public key certificate new user signature public-key certificate [new user encryption public-key certificate] CA system time MAC algorithm id } MAC (key based on authorization code) Upon receipt of the InitClientResponse structure, the client checks that its own system time is sufficiently close to the CA system time, checks the client random number, and validates the MAC. The client then securely stores the new certificates and acknowledges the transaction by sending back the message InitClientConfirm. The fields in this message are protected from modification with a MAC based on the authorization code. InitClientConfirm:: client-to-CA { message type [transaction identifier] Housley, Ford, Farrell, Solo [Page 32]
INTERNET DRAFT November 1995 client random number CA random number MAC algorithm id } MAC (key based on authorization code) Upon receipt of the InitClientConfirm structure, the CA checks the random numbers and validates the MAC. If no errors occur, the CA archives the new user public-key certificate(s). 9.4 User Initialization/Certification with Centrally-Generated Encryption Key Pair 9.4.1 Overview of Exchange This protocol exchange is used to support client initialization, including certificate issuance, for one user, with provision for simultaneously establishing and certifying separate key pairs for digital signature and encryption (or encryption key exchange) purposes. The digital signature key pair is generated by the client. Optionally, a new encryption key pair is generated by (and, optionally, backed up by) a central facility associated with the CA. Prior to conducting this exchange, the user must have registered with the CA, either using the user registration exchange defined in 9.2 or by other means. Following registration, the CA creates a secret data item, called an authorization code, and transfers this data item by out-of-band means to the user. The authorization code is used to establish authentication and integrity protection of the user initialization/certification on-line exchange. This is done by generating a symmetric key based on the authorization code and using this symmetric key for generating Message Authentication Codes (MACs) on all exchanges between client and CA. In the first two messages exchanged, the client sends its user signature public key to the CA and the CA returns the currently valid CA certificate(s). This exchange of public keys allows the client and CA to authenticate each other. If a centrally-generated encryption key pair is to be established, the private key of the newly generated key pair is sent from the CA to the client. The client first generates a protocol encryption key pair and sends the public protocol encryption key to the CA. The CA creates a random symmetric key called the session key and encrypts the user encryption private key with it and then encrypts the session key with the public protocol encryption key it received from the client. The CA sends the encrypted user encryption private key and Housley, Ford, Farrell, Solo [Page 33]
INTERNET DRAFT November 1995 encrypted session key back to the client. The client uses its private protocol decryption key to decrypt the session key and then uses the session key to decrypt the encryption private key. The protocol encryption key pair and session key are discarded after the exchange. 9.4.2 Detailed Description The user receives a reference number and a secret machine-generated authorization code from the CA administrator. Both pieces of information are transferred to the user in a secure manner which preserves their integrity and confidentiality. The reference number is used to uniquely identify the client at the CA and the authorization code is used to secure the exchange integrity-wise. The reference number is used instead of a DN to uniquely identify the client because a DN may be lengthy and difficult for a user to manually type without error. After the reference number and authorization code have been entered by the user, the client generates: - a client random number, - (if a new user signature key pair is required) a new user signature key pair, - (if a new centrally-generated encryption key pair is required) a protocol encryption key pair. The client securely stores locally any new signature private key and/or client-generated encryption private key. The client then sends the message InitCentralRequest to the CA. The entire structure is protected from modification with a MAC based on the authorization code. InitCentralRequest:: client-to-CA { protocol version message type [transaction identifier] [client system time] client random number reference number user signature public key [user signature key id] [protocol encryption key] MAC algorithm id } MAC (key based on authorization code) Upon receipt of the InitCentralRequest structure, if the CA recognizes the reference number and if the protocol version is valid, Housley, Ford, Farrell, Solo [Page 34]
INTERNET DRAFT November 1995 it saves the client random number, generates its own random number (CA random number), and validates the MAC. It then creates: - a new certificate for the user?s digital signature public key, - (if a new centrally-generated encryption key pair is required) a session key, a new user encryption key pair, and a new certificate for the user encryption public key. The CA responds to the client with the message InitCentralResponse. If a new centrally-generated encryption key pair is being generated, the user encryption private key is encrypted using the session key and the session key is encrypted with the protocol encryption public key. The entire structure is protected from modification with a MAC based on the authorization code. InitCentralResponse:: CA-to-client { message type [transaction identifier] client random number CA random number CA signature public key certificate new user signature public-key certificate [new user encryption public-key certificate] [new user encryption private key encrypted with session key] [session key encrypted with protocol encryption key] CA system time MAC algorithm id } MAC (key based on authorization code) Upon receipt of the InitCentralResponse structure, the client checks that its own system time is sufficiently close to the CA system time, checks the client random number, and validates the MAC. If a new centrally-generated encryption key pair is included, the client decrypts the encryption private key. The client then securely stores the new certificates and encryption private key (if present) and acknowledges the transaction by sending back the message InitCentralConfirm. The fields in this message are protected from modification with a MAC based on the authorization code. InitCentralConfirm:: client-to-CA { message type [transaction identifier] client random number CA random number MAC algorithm id } MAC (key based on authorization code) Housley, Ford, Farrell, Solo [Page 35]
INTERNET DRAFT November 1995 Upon receipt of the InitCentralConfirm structure, the CA checks the random numbers and validates the MAC. If no errors occur, the CA archives the new user public-key certificate(s) and (if there is a new centrally-generated encryption key pair and key recovery is to be supported) the encryption private key. 9.5 Encryption Key-Pair Recovery9.5.1 Overview of Exchange This protocol exchange is used to support recovery in the event that a client no longer has a valid signature key pair (due to expiration or revocation), or client system key materials have been lost, e.g., as a result of a forgotten user password. This exchange assumes a system in which an encryption key pair has been centrally generated and backed up (by a central system associated with a CA). This exchange is very similar to the exchange for User Initialization/Certification with Centrally-Generated Encryption Key Pair. The client and CA start without a way to trust one another, i.e., they have no reliable shared key pairs. 9.5.2 Detailed Description The user must first receive, by out-of-band means, a reference number and a secret machine-generated authorization code from the CA administrator. The on-line exchange then consists of a sequence of KeyRecoverRequest, KeyRecoverResponse and KeyRecoverConfirm, which are the same as the exchange in 9.4 except for two differences. First, the CA does not generate (or archive) a new encryption key pair and encryption public-key certificate for the user. Second, the user?s entire encryption key history (list of encryption public-key certificates and matching encryption private keys) are sent back to the client with KeyRecoverResponse. KeyRecoverRequest:: client-to-CA { protocol version message type [transaction identifier] [client system time] client random number reference number user signature public key [user signature key id] protocol encryption key MAC algorithm id } MAC (key based on authorization code) Housley, Ford, Farrell, Solo [Page 36]
INTERNET DRAFT November 1995 KeyRecoverResponse:: CA-to-client { message type [transaction identifier] client random number CA random number CA certificate(s) user encryption private key history encrypted with session key session key encrypted with protocol encryption key user encryption public-key certificate history new user signature public-key certificate CA system time MAC algorithm id } MAC(key based on authorization code) KeyRecoverConfirm:: client-to-CA { message type [transaction identifier] client random number CA random number MAC algorithm id } MAC (key based on authorization code) 9.6 Key Pair Update for Client-Generated Key Pair(s)9.6.1 Overview of Exchange
Guides.rubyonrails.org
1 Why Associations?
In Rails, an association is a connection between two Active Record models. Why do we need associations between models? Because they make common operations simpler and easier in your code. For example, consider a simple Rails application that includes a model for authors and a model for books. Each author can have many books. Without associations, the model declarations would look like this:
Now, suppose we wanted to add a new book for an existing author. We'd need to do something like this:
Or consider deleting an author, and ensuring that all of its books get deleted as well:
With Active Record associations, we can streamline these - and other - operations by declaratively telling Rails that there is a connection between the two models. Here's the revised code for setting up authors and books:
With this change, creating a new book for a particular author is easier:
Deleting an author and all of its books is much easier:
To learn more about the different types of associations, read the next section of this guide. That's followed by some tips and tricks for working with associations, and then by a complete reference to the methods and options for associations in Rails.
2 The Types of Associations
Rails supports six types of associations:
Associations are implemented using macro-style calls, so that you can declaratively add features to your models. For example, by declaring that one model another, you instruct Rails to maintain Primary Key-Foreign Key information between instances of the two models, and you also get a number of utility methods added to your model.
In the remainder of this guide, you'll learn how to declare and use the various forms of associations. But first, a quick introduction to the situations where each association type is appropriate.
2.1 The Association
A association sets up a one-to-one connection with another model, such that each instance of the declaring model "belongs to" one instance of the other model. For example, if your application includes authors and books, and each book can be assigned to exactly one author, you'd declare the book model this way:
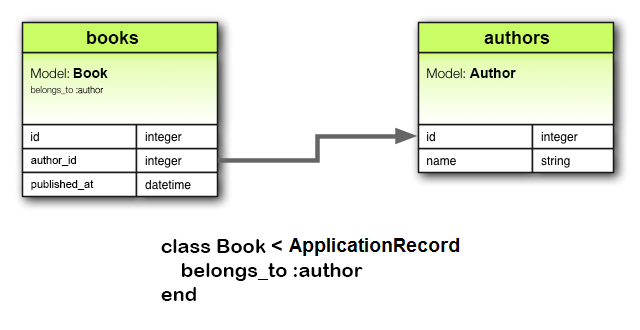
associations must use the singular term. If you used the pluralized form in the above example for the association in the model and tried to create the instance by , you would be told that there was an "uninitialized constant Book::Authors". This is because Rails automatically infers the class name from the association name. If the association name is wrongly pluralized, then the inferred class will be wrongly pluralized too.
The corresponding migration might look like this:
2.2 The Association
A association also sets up a one-to-one connection with another model, but with somewhat different semantics (and consequences). This association indicates that each instance of a model contains or possesses one instance of another model. For example, if each supplier in your application has only one account, you'd declare the supplier model like this:
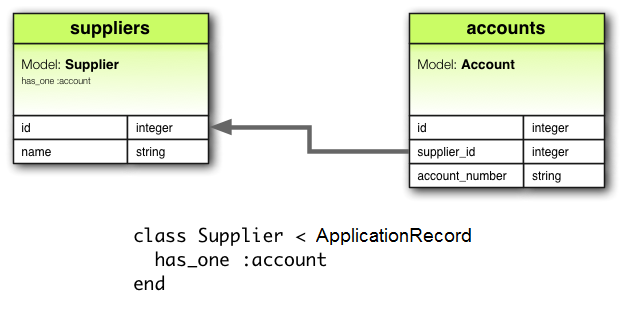
The corresponding migration might look like this:
Depending on the use case, you might also need to create a unique index and/or a foreign key constraint on the supplier column for the accounts table. In this case, the column definition might look like this:
2.3 The Association
A association indicates a one-to-many connection with another model. You'll often find this association on the "other side" of a association. This association indicates that each instance of the model has zero or more instances of another model. For example, in an application containing authors and books, the author model could be declared like this:
The name of the other model is pluralized when declaring a association.
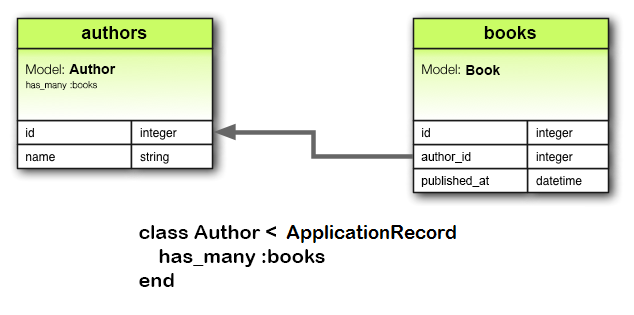
The corresponding migration might look like this:
2.4 The Association
A association is often used to set up a many-to-many connection with another model. This association indicates that the declaring model can be matched with zero or more instances of another model by proceeding through a third model. For example, consider a medical practice where patients make appointments to see physicians. The relevant association declarations could look like this:
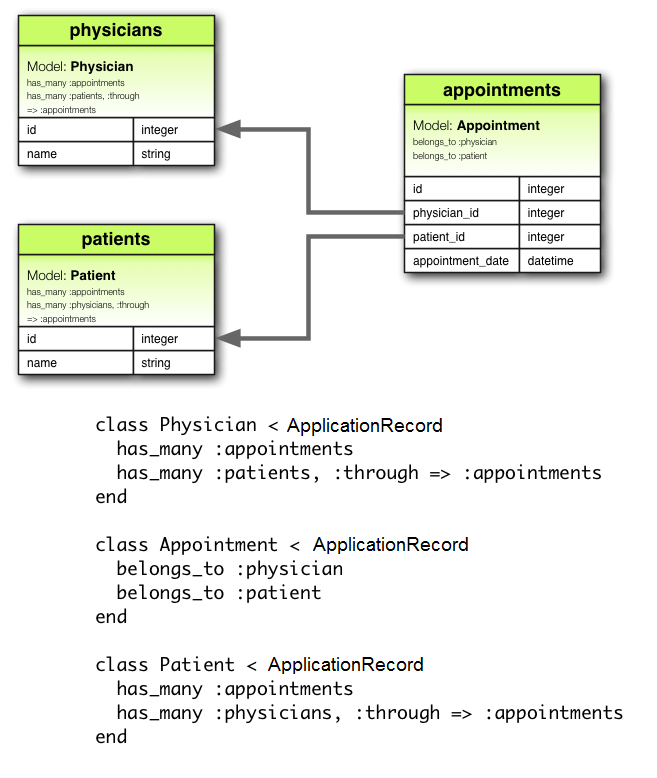
The corresponding migration might look like this:
The collection of join models can be managed via the association methods. For example, if you assign:
Then new join models are automatically created for the newly associated objects. If some that existed previously are now missing, then their join rows are automatically deleted.
Automatic deletion of join models is direct, no destroy callbacks are triggered.
The association is also useful for setting up "shortcuts" through nested associations. For example, if a document has many sections, and a section has many paragraphs, you may sometimes want to get a simple collection of all paragraphs in the document. You could set that up this way:
With specified, Rails will now understand:
2.5 The Association
A association sets up a one-to-one connection with another model. This association indicates that the declaring model can be matched with one instance of another model by proceeding through a third model. For example, if each supplier has one account, and each account is associated with one account history, then the supplier model could look like this:
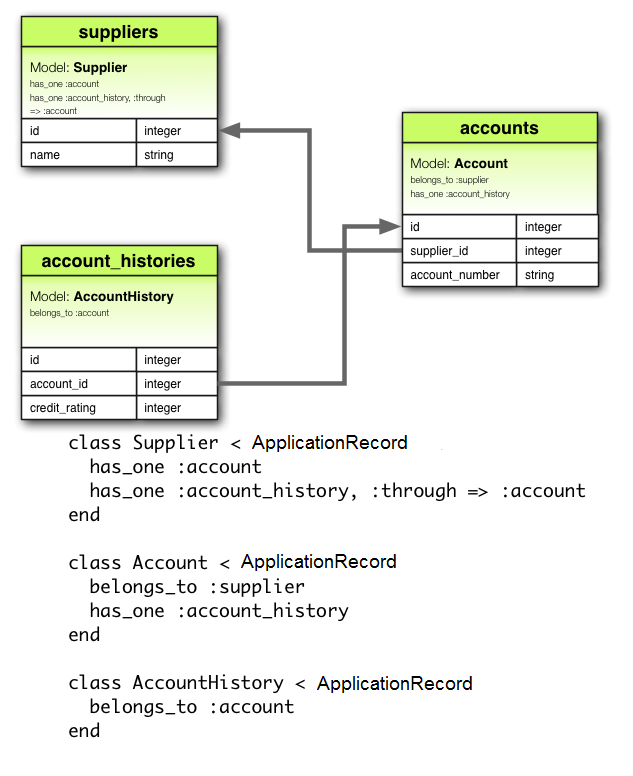
The corresponding migration might look like this:
2.6 The Association
A association creates a direct many-to-many connection with another model, with no intervening model. For example, if your application includes assemblies and parts, with each assembly having many parts and each part appearing in many assemblies, you could declare the models this way:
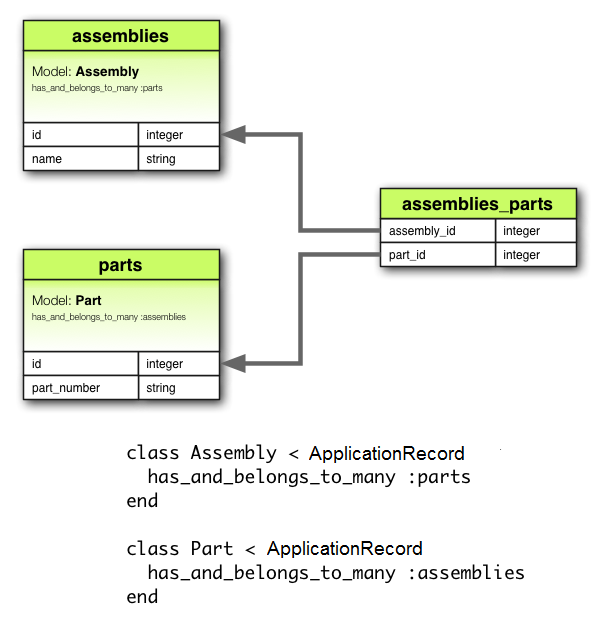
The corresponding migration might look like this:
2.7 Choosing Between and
If you want to set up a one-to-one relationship between two models, you'll need to add to one, and to the other. How do you know which is which?
The distinction is in where you place the foreign key (it goes on the table for the class declaring the association), but you should give some thought to the actual meaning of the data as well. The relationship says that one of something is yours - that is, that something points back to you. For example, it makes more sense to say that a supplier owns an account than that an account owns a supplier. This suggests that the correct relationships are like this:
The corresponding migration might look like this:
Using makes the foreign key naming obvious and explicit. In current versions of Rails, you can abstract away this implementation detail by using instead.
2.8 Choosing Between and
Rails offers two different ways to declare a many-to-many relationship between models. The simpler way is to use , which allows you to make the association directly:
The second way to declare a many-to-many relationship is to use . This makes the association indirectly, through a join model:
The simplest rule of thumb is that you should set up a relationship if you need to work with the relationship model as an independent entity. If you don't need to do anything with the relationship model, it may be simpler to set up a relationship (though you'll need to remember to create the joining table in the database).
You should use if you need validations, callbacks, or extra attributes on the join model.
2.9 Polymorphic Associations
A slightly more advanced twist on associations is the polymorphic association. With polymorphic associations, a model can belong to more than one other model, on a single association. For example, you might have a picture model that belongs to either an employee model or a product model. Here's how this could be declared:
You can think of a polymorphic declaration as setting up an interface that any other model can use. From an instance of the model, you can retrieve a collection of pictures: .
Similarly, you can retrieve .
If you have an instance of the model, you can get to its parent via . To make this work, you need to declare both a foreign key column and a type column in the model that declares the polymorphic interface:
This migration can be simplified by using the form:
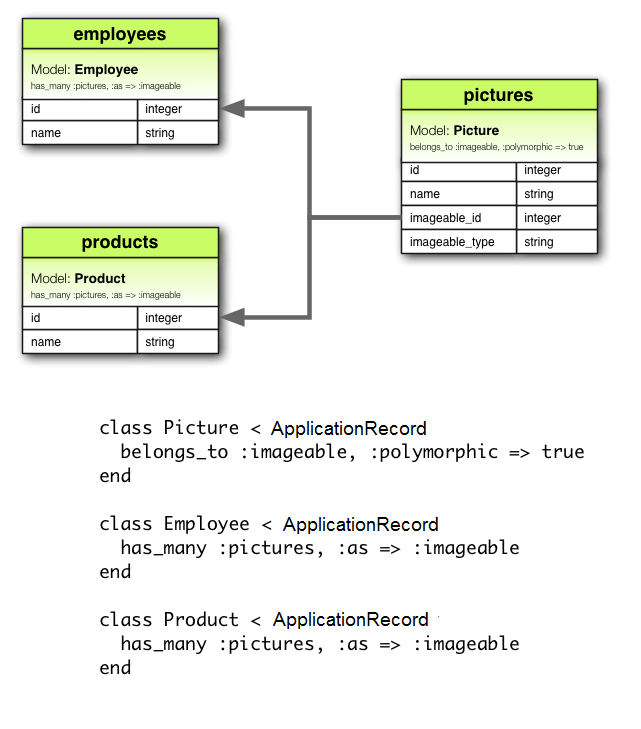
2.10 Self Joins
In designing a data model, you will sometimes find a model that should have a relation to itself. For example, you may want to store all employees in a single database model, but be able to trace relationships such as between manager and subordinates. This situation can be modeled with self-joining associations:
With this setup, you can retrieve and .
In your migrations/schema, you will add a references column to the model itself.
3 Tips, Tricks, and Warnings
Here are a few things you should know to make efficient use of Active Record associations in your Rails applications:
- Controlling caching
- Avoiding name collisions
- Updating the schema
- Controlling association scope
- Bi-directional associations
3.1 Controlling Caching
All of the association methods are built around caching, which keeps the result of the most recent query available for further operations. The cache is even shared across methods. For example:
But what if you want to reload the cache, because data might have been changed by some other part of the application? Just call on the association:
3.2 Avoiding Name Collisions
You are not free to use just any name for your associations. Because creating an association adds a method with that name to the model, it is a bad idea to give an association a name that is already used for an instance method of . The association method would override the base method and break things. For instance, or are bad names for associations.
3.3 Updating the Schema
Associations are extremely useful, but they are not magic. You are responsible for maintaining your database schema to match your associations. In practice, this means two things, depending on what sort of associations you are creating. For associations you need to create foreign keys, and for associations you need to create the appropriate join table.
3.3.1 Creating Foreign Keys for Associations
When you declare a association, you need to create foreign keys as appropriate. For example, consider this model:
This declaration needs to be backed up by a corresponding foreign key column in the books table. For a brand new table, the migration might look something like this:
Whereas for an existing table, it might look like this:
If you wish to enforce referential integrity at the database level, add the option to the ‘reference’ column declarations above.
3.3.2 Creating Join Tables for Associations
If you create a association, you need to explicitly create the joining table. Unless the name of the join table is explicitly specified by using the option, Active Record creates the name by using the lexical order of the class names. So a join between author and book models will give the default join table name of "authors_books" because "a" outranks "b" in lexical ordering.
The precedence between model names is calculated using the operator for . This means that if the strings are of different lengths, and the strings are equal when compared up to the shortest length, then the longer string is considered of higher lexical precedence than the shorter one. For example, one would expect the tables "paper_boxes" and "papers" to generate a join table name of "papers_paper_boxes" because of the length of the name "paper_boxes", but it in fact generates a join table name of "paper_boxes_papers" (because the underscore '_' is lexicographically less than 's' in common encodings).
Whatever the name, you must manually generate the join table with an appropriate migration. For example, consider these associations:
These need to be backed up by a migration to create the table. This table should be created without a primary key:
We pass to because that table does not represent a model. That's required for the association to work properly. If you observe any strange behavior in a association like mangled model IDs, or exceptions about conflicting IDs, chances are you forgot that bit.
You can also use the method
3.4 Controlling Association Scope
By default, associations look for objects only within the current module's scope. This can be important when you declare Active Record models within a module. For example:
This will work fine, because both the and the class are defined within the same scope. But the following will not work, because and are defined in different scopes:
To associate a model with a model in a different namespace, you must specify the complete class name in your association declaration:
3.5 Bi-directional Associations
It's normal for associations to work in two directions, requiring declaration on two different models:
Active Record will attempt to automatically identify that these two models share a bi-directional association based on the association name. In this way, Active Record will only load one copy of the object, making your application more efficient and preventing inconsistent data:
Active Record supports automatic identification for most associations with standard names. However, Active Record will not automatically identify bi-directional associations that contain a scope or any of the following options:
For example, consider the following model declarations:
Active Record will no longer automatically recognize the bi-directional association:
Active Record provides the option so you can explicitly declare bi-directional associations:
By including the option in the association declaration, Active Record will now recognize the bi-directional association:
4 Detailed Association Reference
The following sections give the details of each type of association, including the methods that they add and the options that you can use when declaring an association.
4.1 Association Reference
The association creates a one-to-one match with another model. In database terms, this association says that this class contains the foreign key. If the other class contains the foreign key, then you should use instead.
4.1.1 Methods Added by
When you declare a association, the declaring class automatically gains 6 methods related to the association:
In all of these methods, is replaced with the symbol passed as the first argument to . For example, given the declaration:
Each instance of the model will have these methods:
When initializing a new or association you must use the prefix to build the association, rather than the method that would be used for or associations. To create one, use the prefix.
4.1.1.1
The method returns the associated object, if any. If no associated object is found, it returns .
If the associated object has already been retrieved from the database for this object, the cached version will be returned. To override this behavior (and force a database read), call on the parent object.
4.1.1.2
The method assigns an associated object to this object. Behind the scenes, this means extracting the primary key from the associated object and setting this object's foreign key to the same value.
4.1.1.3
The method returns a new object of the associated type. This object will be instantiated from the passed attributes, and the link through this object's foreign key will be set, but the associated object will not yet be saved.
4.1.1.4
The method returns a new object of the associated type. This object will be instantiated from the passed attributes, the link through this object's foreign key will be set, and, once it passes all of the validations specified on the associated model, the associated object will be saved.
4.1.1.5
Does the same as above, but raises if the record is invalid.
4.1.2 Options for
While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the association reference. Such customizations can easily be accomplished by passing options and scope blocks when you create the association. For example, this association uses two such options:
The association supports these options:
4.1.2.1
If you set the option to , Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting to is not the same as not setting the option. If the option is not present, then new associated objects will be saved, but updated associated objects will not be saved.
4.1.2.2
If the name of the other model cannot be derived from the association name, you can use the option to supply the model name. For example, if a book belongs to an author, but the actual name of the model containing authors is , you'd set things up this way:
4.1.2.3
The option can be used to make finding the number of belonging objects more efficient. Consider these models:
With these declarations, asking for the value of requires making a call to the database to perform a query. To avoid this call, you can add a counter cache to the belonging model:
With this declaration, Rails will keep the cache value up to date, and then return that value in response to the method.
Although the option is specified on the model that includes the declaration, the actual column must be added to the associated () model. In the case above, you would need to add a column named to the model.
You can override the default column name by specifying a custom column name in the declaration instead of . For example, to use instead of :
You only need to specify the option on the side of the association.
Counter cache columns are added to the containing model's list of read-only attributes through .
4.1.2.4
If you set the option to:
- , when the object is destroyed, will be called on its associated objects.
- , when the object is destroyed, all its associated objects will be deleted directly from the database without calling their method.
You should not specify this option on a association that is connected with a association on the other class. Doing so can lead to orphaned records in your database.
4.1.2.5
By convention, Rails assumes that the column used to hold the foreign key on this model is the name of the association with the suffix added. The option lets you set the name of the foreign key directly:
In any case, Rails will not create foreign key columns for you. You need to explicitly define them as part of your migrations.
4.1.2.6
By convention, Rails assumes that the column is used to hold the primary key of its tables. The option allows you to specify a different column.
For example, given we have a table with as the primary key. If we want a separate table to hold the foreign key in the column, then we can use to achieve this like so:
When we execute then the record will have its value as the value of .
4.1.2.7
The option specifies the name of the or association that is the inverse of this association.
4.1.2.8
Passing to the option indicates that this is a polymorphic association. Polymorphic associations were discussed in detail earlier in this guide.
4.1.2.9
If you set the option to , then the or timestamp on the associated object will be set to the current time whenever this object is saved or destroyed:
In this case, saving or destroying a book will update the timestamp on the associated author. You can also specify a particular timestamp attribute to update:
4.1.2.10
If you set the option to , then associated objects will be validated whenever you save this object. By default, this is : associated objects will not be validated when this object is saved.
4.1.2.11
If you set the option to , then the presence of the associated object won't be validated. By default, this option is set to .
4.1.3 Scopes for
There may be times when you wish to customize the query used by . Such customizations can be achieved via a scope block. For example:
You can use any of the standard querying methods inside the scope block. The following ones are discussed below:
4.1.3.1
The method lets you specify the conditions that the associated object must meet.
4.1.3.2
You can use the method to specify second-order associations that should be eager-loaded when this association is used. For example, consider these models:
If you frequently retrieve authors directly from chapters (), then you can make your code somewhat more efficient by including authors in the association from chapters to books:
There's no need to use for immediate associations - that is, if you have , then the author is eager-loaded automatically when it's needed.
4.1.3.3
If you use , then the associated object will be read-only when retrieved via the association.
4.1.3.4
The method lets you override the SQL clause that is used to retrieve data about the associated object. By default, Rails retrieves all columns.
If you use the method on a association, you should also set the option to guarantee the correct results.
4.1.4 Do Any Associated Objects Exist?
You can see if any associated objects exist by using the method:
4.1.5 When are Objects Saved?
Assigning an object to a association does not automatically save the object. It does not save the associated object either.
4.2 Association Reference
The association creates a one-to-one match with another model. In database terms, this association says that the other class contains the foreign key. If this class contains the foreign key, then you should use instead.
4.2.1 Methods Added by
When you declare a association, the declaring class automatically gains 6 methods related to the association:
In all of these methods, is replaced with the symbol passed as the first argument to . For example, given the declaration:
Each instance of the model will have these methods:
When initializing a new or association you must use the prefix to build the association, rather than the method that would be used for or associations. To create one, use the prefix.
4.2.1.1
The method returns the associated object, if any. If no associated object is found, it returns .
If the associated object has already been retrieved from the database for this object, the cached version will be returned. To override this behavior (and force a database read), call on the parent object.
4.2.1.2
The method assigns an associated object to this object. Behind the scenes, this means extracting the primary key from this object and setting the associated object's foreign key to the same value.
4.2.1.3
The method returns a new object of the associated type. This object will be instantiated from the passed attributes, and the link through its foreign key will be set, but the associated object will not yet be saved.
4.2.1.4
The method returns a new object of the associated type. This object will be instantiated from the passed attributes, the link through its foreign key will be set, and, once it passes all of the validations specified on the associated model, the associated object will be saved.
4.2.1.5
Does the same as above, but raises if the record is invalid.
4.2.2 Options for
While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the association reference. Such customizations can easily be accomplished by passing options when you create the association. For example, this association uses two such options:
The association supports these options:
4.2.2.1
Setting the option indicates that this is a polymorphic association. Polymorphic associations were discussed in detail earlier in this guide.
4.2.2.2
If you set the option to , Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting to is not the same as not setting the option. If the option is not present, then new associated objects will be saved, but updated associated objects will not be saved.
4.2.2.3
If the name of the other model cannot be derived from the association name, you can use the option to supply the model name. For example, if a supplier has an account, but the actual name of the model containing accounts is , you'd set things up this way:
4.2.2.4
Controls what happens to the associated object when its owner is destroyed:
- causes the associated object to also be destroyed
- causes the associated object to be deleted directly from the database (so callbacks will not execute)
- causes the foreign key to be set to . Polymorphic type column is also nullified on polymorphic associations. Callbacks are not executed.
- causes an exception to be raised if there is an associated record
- causes an error to be added to the owner if there is an associated object
It's necessary not to set or leave option for those associations that have database constraints. If you don't set to destroy such associations you won't be able to change the associated object because the initial associated object's foreign key will be set to the unallowed value.
4.2.2.5
By convention, Rails assumes that the column used to hold the foreign key on the other model is the name of this model with the suffix added. The option lets you set the name of the foreign key directly:
In any case, Rails will not create foreign key columns for you. You need to explicitly define them as part of your migrations.
4.2.2.6
The option specifies the name of the association that is the inverse of this association.
4.2.2.7
By convention, Rails assumes that the column used to hold the primary key of this model is . You can override this and explicitly specify the primary key with the option.
4.2.2.8
The option specifies the source association name for a association.
4.2.2.9
The option specifies the source association type for a association that proceeds through a polymorphic association.
4.2.2.10
The option specifies a join model through which to perform the query. associations were discussed in detail earlier in this guide.
4.2.2.11
If you set the option to , then the or timestamp on the associated object will be set to the current time whenever this object is saved or destroyed:
In this case, saving or destroying a supplier will update the timestamp on the associated account. You can also specify a particular timestamp attribute to update:
4.2.2.12
If you set the option to , then associated objects will be validated whenever you save this object. By default, this is : associated objects will not be validated when this object is saved.
4.2.3 Scopes for
There may be times when you wish to customize the query used by . Such customizations can be achieved via a scope block. For example:
You can use any of the standard querying methods inside the scope block. The following ones are discussed below:
4.2.3.1
The method lets you specify the conditions that the associated object must meet.
4.2.3.2
You can use the method to specify second-order associations that should be eager-loaded when this association is used. For example, consider these models:
If you frequently retrieve representatives directly from suppliers (), then you can make your code somewhat more efficient by including representatives in the association from suppliers to accounts:
4.2.3.3
If you use the method, then the associated object will be read-only when retrieved via the association.
4.2.3.4
The method lets you override the SQL clause that is used to retrieve data about the associated object. By default, Rails retrieves all columns.
4.2.4 Do Any Associated Objects Exist?
You can see if any associated objects exist by using the method:
4.2.5 When are Objects Saved?
When you assign an object to a association, that object is automatically saved (in order to update its foreign key). In addition, any object being replaced is also automatically saved, because its foreign key will change too.
If either of these saves fails due to validation errors, then the assignment statement returns and the assignment itself is cancelled.
If the parent object (the one declaring the association) is unsaved (that is, returns ) then the child objects are not saved. They will automatically when the parent object is saved.
If you want to assign an object to a association without saving the object, use the method.
4.3 Association Reference
The association creates a one-to-many relationship with another model. In database terms, this association says that the other class will have a foreign key that refers to instances of this class.
4.3.1 Methods Added by
When you declare a association, the declaring class automatically gains 17 methods related to the association:
In all of these methods, is replaced with the symbol passed as the first argument to , and is replaced with the singularized version of that symbol. For example, given the declaration:
Each instance of the model will have these methods:
4.3.1.1
The method returns a Relation of all of the associated objects. If there are no associated objects, it returns an empty Relation.
4.3.1.2
The method adds one or more objects to the collection by setting their foreign keys to the primary key of the calling model.
4.3.1.3
The method removes one or more objects from the collection by setting their foreign keys to .
Additionally, objects will be destroyed if they're associated with , and deleted if they're associated with .
4.3.1.4
The method removes one or more objects from the collection by running on each object.
Objects will always be removed from the database, ignoring the option.
4.3.1.5
The method makes the collection contain only the supplied objects, by adding and deleting as appropriate. The changes are persisted to the database.
4.3.1.6
The method returns an array of the ids of the objects in the collection.
4.3.1.7
The method makes the collection contain only the objects identified by the supplied primary key values, by adding and deleting as appropriate. The changes are persisted to the database.
4.3.1.8
The method removes all objects from the collection according to the strategy specified by the option. If no option is given, it follows the default strategy. The default strategy for associations is , and for associations is to set the foreign keys to .
Objects will be deleted if they're associated with , just like .
4.3.1.9
The method returns if the collection does not contain any associated objects.
4.3.1.10
The method returns the number of objects in the collection.
4.3.1.11
The method finds objects within the collection. It uses the same syntax and options as .
4.3.1.12
The method finds objects within the collection based on the conditions supplied but the objects are loaded lazily meaning that the database is queried only when the object(s) are accessed.
4.3.1.13
The method checks whether an object meeting the supplied conditions exists in the collection. It uses the same syntax and options as .
4.3.1.14
The method returns a single or array of new objects of the associated type. The object(s) will be instantiated from the passed attributes, and the link through their foreign key will be created, but the associated objects will not yet be saved.
4.3.1.15
The method returns a single or array of new objects of the associated type. The object(s) will be instantiated from the passed attributes, the link through its foreign key will be created, and, once it passes all of the validations specified on the associated model, the associated object will be saved.
4.3.1.16
Does the same as above, but raises if the record is invalid.
4.3.1.17
The method returns a Relation of all of the associated objects, forcing a database read. If there are no associated objects, it returns an empty Relation.
4.3.2 Options for
While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the association reference. Such customizations can easily be accomplished by passing options when you create the association. For example, this association uses two such options:
The association supports these options:
4.3.2.1
Setting the option indicates that this is a polymorphic association, as discussed earlier in this guide.
4.3.2.2
If you set the option to , Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting to is not the same as not setting the option. If the option is not present, then new associated objects will be saved, but updated associated objects will not be saved.
4.3.2.3
If the name of the other model cannot be derived from the association name, you can use the option to supply the model name. For example, if an author has many books, but the actual name of the model containing books is , you'd set things up this way:
4.3.2.4
This option can be used to configure a custom named . You only need this option when you customized the name of your on the belongs_to association.
4.3.2.5
Controls what happens to the associated objects when their owner is destroyed:
- causes all the associated objects to also be destroyed
- causes all the associated objects to be deleted directly from the database (so callbacks will not execute)
- causes the foreign key to be set to
What’s New in the Easy Macro Recorder 4.2.5 serial key or number?
Screen Shot
System Requirements for Easy Macro Recorder 4.2.5 serial key or number
- First, download the Easy Macro Recorder 4.2.5 serial key or number
-
You can download its setup from given links:

Easy Macro Recorder 4.2.5 serial key or number & Apps for Laptop & PC Free Download

Easy Macro Recorder 4.2.5 serial key or number& Software
